UK AI Security Institute study shows standard benchmarks underestimate AI agent capabilities due to compute budget caps
By
Matthias Bastian
Summary
The UK's AI Security Institute (AISI) conducted a study across seven benchmarks showing that standard AI evaluations systematically underestimate agent capabilities by capping test-time compute budgets. When the token budget was increased tenfold on software engineering tasks, success rates jumped about 25 percent. Newer models benefit most from increased compute budgets, and the actual progress at the frontier is about 60 percent steeper than previous measurements suggested. The research demonstrates that AI agent performance follows a curve that rises with test-time compute, and fixed budget caps measure the minimum rather than the maximum capability.
Source

 bskyUK AI Security Institute study shows standard benchmarks underestimate AI agent capabilities due to compute budget capsthe-decoder.com
bskyUK AI Security Institute study shows standard benchmarks underestimate AI agent capabilities due to compute budget capsthe-decoder.comKey quotes
· 5 pulledFixed budget caps systematically underestimate how capable AI agents really are.
An AI agent's performance is a curve that rises with test-time compute, the amount of processing power an agent is allowed to burn while working on a task.
Cut the budget while the curve is still climbing, and the measured score tells you the minimum, not the maximum.
On software engineering tasks, success rates jumped about 25 percent when the token budget was increased tenfold.
Actual progress at the frontier is about 60 percent steeper than previous measurements suggested.
You might also wanna read

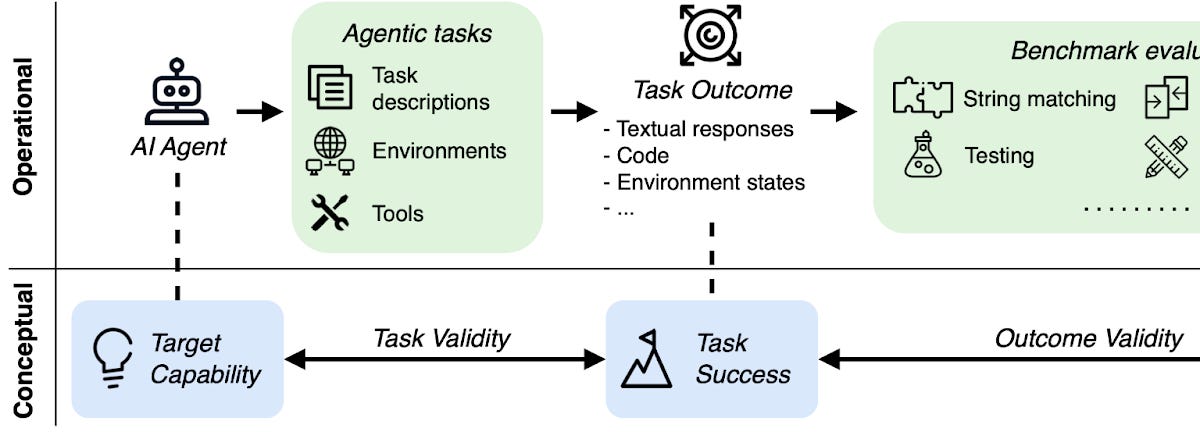
Why Current AI Agent Benchmarks Are Unreliable and Misleading
The article argues that current AI agent benchmarks are fundamentally flawed and unreliable. Unlike traditional AI benchmarks, agent benchma

Research Study: AI Agents vs Human Cybersecurity Professionals in Penetration Testing
This research paper presents the first comprehensive evaluation comparing AI agents to human cybersecurity professionals in real-world penet
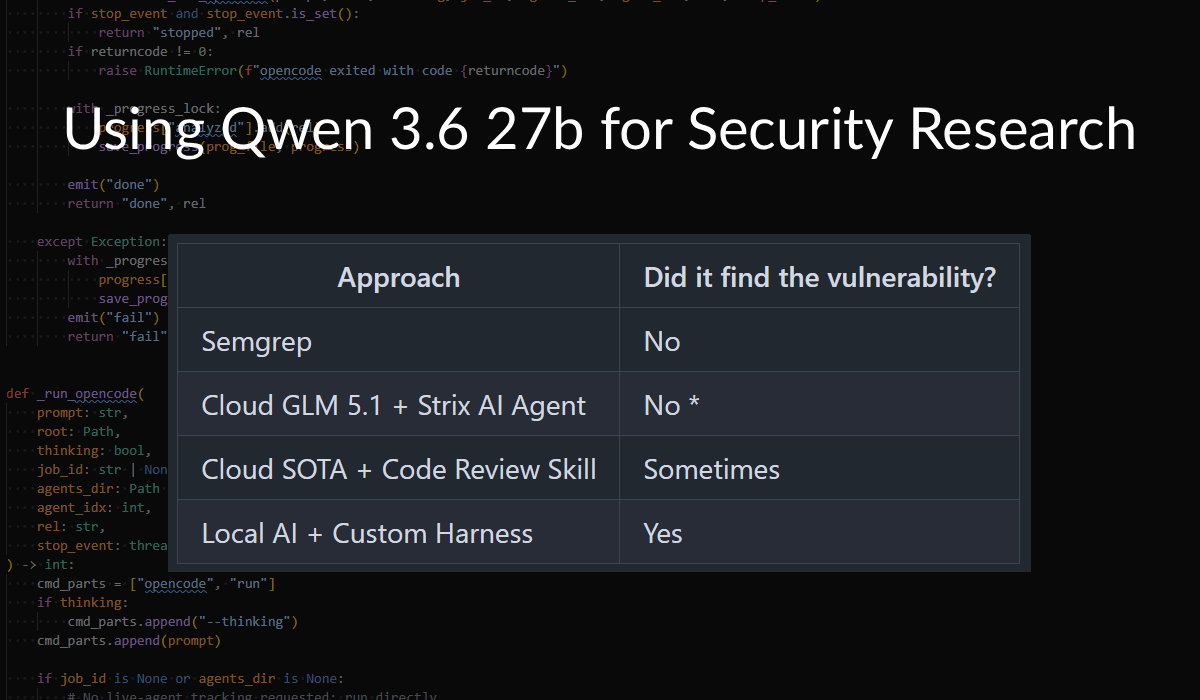
Benchmarking Local AI Models for Cybersecurity Vulnerability Detection
The article evaluates the effectiveness of local AI models for cybersecurity penetration testing and vulnerability research. The author benc
 projectblack.io·6d ago
projectblack.io·6d ago
Why compute-based AI regulations are becoming obsolete: Three key challenges
This article examines the growing inadequacy of using pre-training compute as a proxy for AI model capabilities in regulatory frameworks lik
 epoch.ai·8d ago
epoch.ai·8d agoHow We Broke Top AI Agent Benchmarks: And What Comes Next

AI Security Benchmark Results: Cloud vs Local Model Performance Comparison
The article presents benchmark results from HomeSec-Bench, a comprehensive evaluation of AI models for security applications. The benchmark
 sharpai.org·3mo ago
sharpai.org·3mo ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.