Benchmarking Local AI Models for Cybersecurity Vulnerability Detection
By
Eddie Zhang
Summary
The article evaluates the effectiveness of local AI models for cybersecurity penetration testing and vulnerability research. The author benchmarks four different AI approaches to identify a known vulnerability, assessing how competent local models have become compared to cloud-based solutions like Anthropic's. Key findings address the trade-offs between cost, privacy, and thoroughness in AI-assisted security work, noting that while model intelligence has progressed significantly, concerns about privacy and the gamble of incomplete analysis remain.
Source
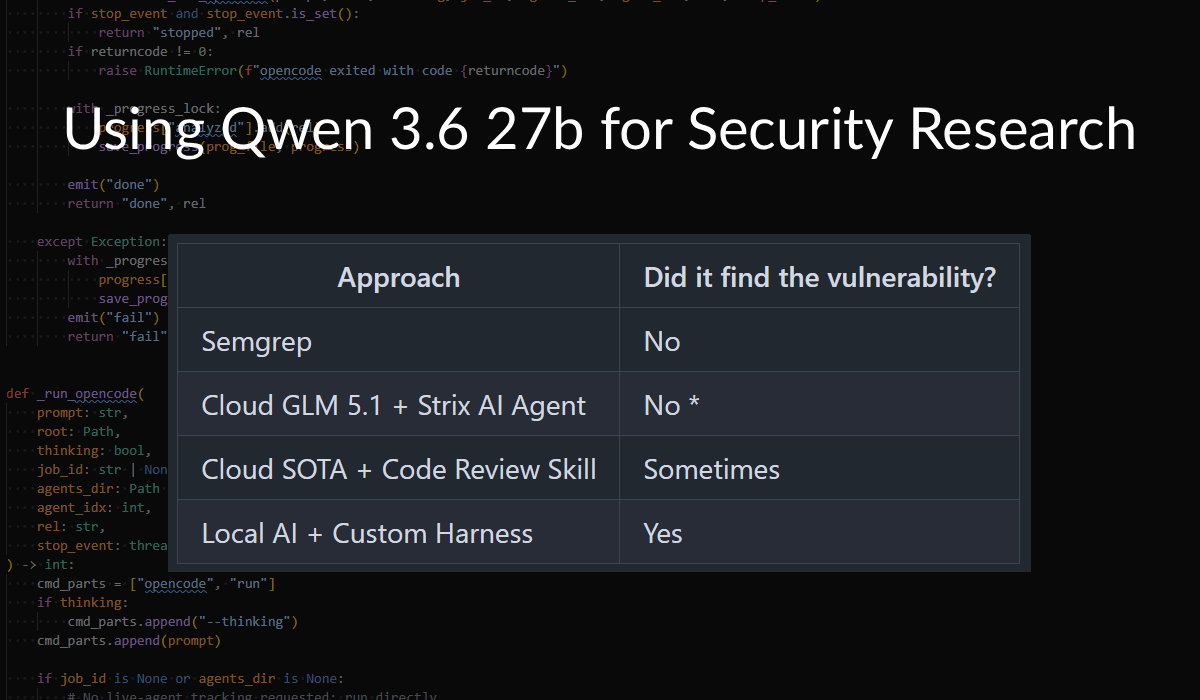
 Twitter / XBenchmarking Local AI Models for Cybersecurity Vulnerability Detectionprojectblack.io
Twitter / XBenchmarking Local AI Models for Cybersecurity Vulnerability Detectionprojectblack.ioKey quotes
· 4 pulledThere's a lot of hype around the research Anthropic is publishing; however, cost and privacy are still problems.
When there's no guarantee that a thorough job was performed, this turns assurance work into something that feels more like gambling.
Just one more run! 'Make no mistakes, be thorough'
Model intelligence and tradecraft have progressed a lot in the year that's passed since I last tried something similar.
You might also wanna read


AI Security Benchmark Results: Cloud vs Local Model Performance Comparison
The article presents benchmark results from HomeSec-Bench, a comprehensive evaluation of AI models for security applications. The benchmark
 sharpai.org·3mo ago
sharpai.org·3mo ago
How AI-powered cybersecurity tools are outpacing human teams in vulnerability detection
The article covers the race to adapt cybersecurity in an AI-powered world, focusing on XBOW's autonomous offensive security platform that us
 cyberscoop.com·22d ago
cyberscoop.com·22d ago
Public AI Models Already Possess Vulnerability Research Capabilities Similar to Anthropic's Mythos
The article challenges Anthropic's claim that advanced AI vulnerability research needs restricted access, arguing that public models already
 blog.vidocsecurity.com·2mo ago
blog.vidocsecurity.com·2mo ago
Mapping AI-Powered Cyberattacks to the MITRE ATT&CK Framework
Security researchers Kyla Guru, Alex Moix, and Jacob Klein present a new analysis mapping real-world AI-powered cyberattacks onto the MITRE
 red.anthropic.com·21d ago
red.anthropic.com·21d ago
Research Study: AI Agents vs Human Cybersecurity Professionals in Penetration Testing
This research paper presents the first comprehensive evaluation comparing AI agents to human cybersecurity professionals in real-world penet

SIR-Bench: A Benchmark for Evaluating Autonomous Security Incident Response Agents
Researchers introduce SIR-Bench, a comprehensive benchmark for evaluating autonomous security incident response agents. The benchmark consis
Comments
Sign in to join the conversation.
No comments yet. Be the first.