SIR-Bench: A Benchmark for Evaluating Autonomous Security Incident Response Agents
By
dan_l2
A bagel you'd recommend to a friend without hedging.
Summary
Researchers introduce SIR-Bench, a comprehensive benchmark for evaluating autonomous security incident response agents. The benchmark consists of 794 test cases derived from 129 anonymized real-world incident patterns with expert-validated ground truth. SIR-Bench distinguishes between genuine forensic investigation and simple alert parroting by measuring not just triage accuracy but also novel evidence discovery through active investigation. The framework uses Once Upon A Threat (OUAT) to replay real incidents in controlled cloud environments, producing authentic telemetry. Evaluation uses three metrics: triage accuracy, novel finding discovery, and tool usage appropriateness, assessed through an adversarial LLM-as-Judge that requires concrete forensic evidence. Initial evaluation shows 97.1% true positive detection, 73.4% false positive rejection, and 5.67 novel key findings per case.
Key quotes
· 5 pulledSIR-Bench measures not only whether agents reach correct triage decisions, but whether they discover novel evidence through active investigation.
Our evaluation methodology introduces three complementary metrics: triage accuracy (M1), novel finding discovery (M2), and tool usage appropriateness (M3).
Evaluating our SIR agent on the benchmark demonstrates 97.1% true positive (TP) detection, 73.4% false positive (FP) rejection, and 5.67 novel key findings per case.
SIR-Bench distinguishes genuine forensic investigation from alert parroting.
Derived from 129 anonymized incident patterns with expert-validated ground truth.
You might also wanna read

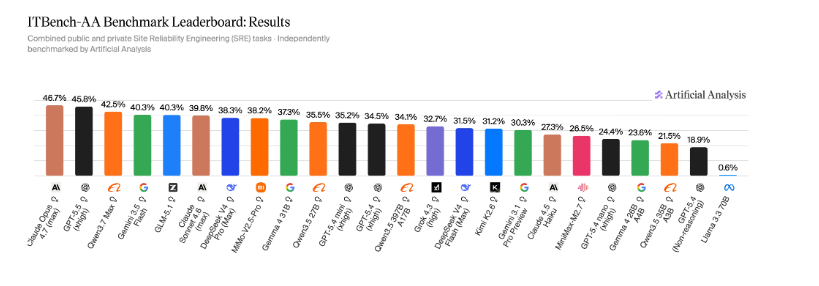
ITBench-AA Benchmark Launched: Frontier AI Models Score Below 50% on Enterprise IT Tasks
Artificial Analysis and IBM Software Innovation Lab have launched ITBench-AA, a new benchmark series evaluating AI models on agentic enterpr
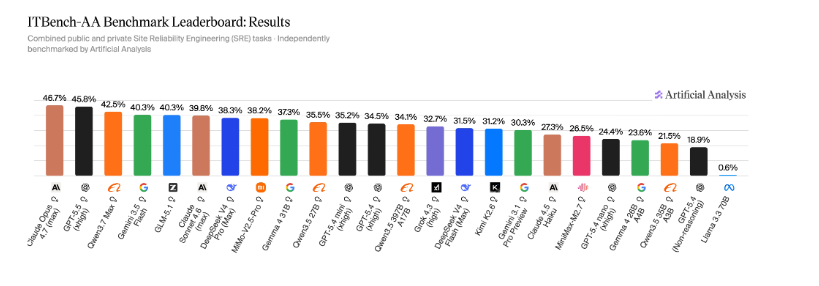
New ITBench-AA Benchmark Reveals AI Models Struggle with Enterprise SRE Tasks
ITBench-AA, a new benchmark developed by Artificial Analysis and IBM Research over six months, reveals that leading AI models like Claude Op