New ITBench-AA Benchmark Reveals AI Models Struggle with Enterprise SRE Tasks
Models perform poorly on new benchmark, highlighting gaps for AI in enterprise IT.
Read the full articleYou might also wanna read

EdgeBench: A Benchmark for Measuring AI Environment Learning Through Extended Real-World Tasks
EdgeBench studies how agents learn from real-world environments across 134 day-long executable tasks.

AI Security Benchmark Results: Cloud vs Local Model Performance Comparison
Qwen3.5-9B scores 93.8% on 96 real security AI tests — within 4 points of GPT-5.4 — running entirely on Apple Silicon. Full benchmark result
 sharpai.org·3mo ago
sharpai.org·3mo ago
SkillsBench: A Benchmark for Evaluating AI Agent Skills Across Diverse Tasks
Agent Skills are structured packages of procedural knowledge that augment LLM agents at inference time. Despite rapid adoption, there is no

ProgramBench: New Benchmark Reveals Language Models Struggle to Build Complete Software Projects From Scratch
Turning ideas into full software projects from scratch has become a popular use case for language models. Agents are being deployed to seed,
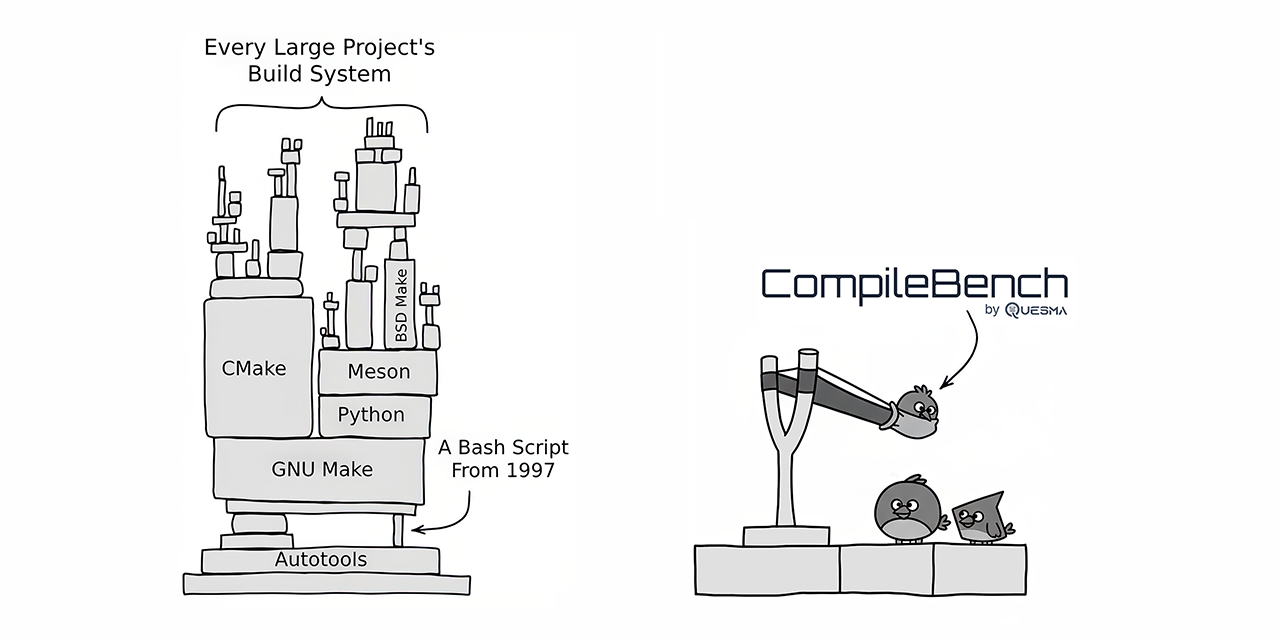
CompileBench: Testing AI Models on Real-World Software Engineering Challenges
We tested 19 LLMs on their ability to handle real-world software engineering tasks like compiling old code and cross-compiling. See how Anth
 quesma.com·9mo ago
quesma.com·9mo ago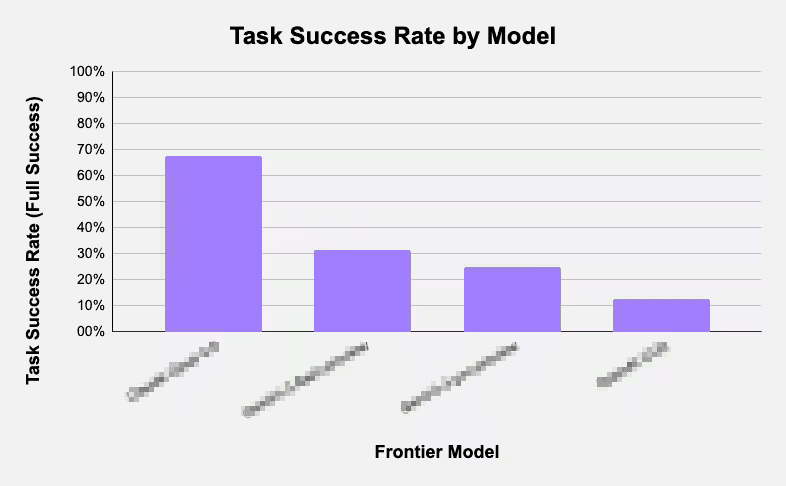
PA Bench: A New Benchmark for Evaluating AI Web Agents on Real-World Personal Assistant Workflows
We're creating reinforcement learning environments for AI agents.
 vibrantlabs.com·4mo ago
vibrantlabs.com·4mo ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.