AI Security Benchmark Results: Cloud vs Local Model Performance Comparison
By
aegis_camera
Hot, fresh, and worth queueing round the block for.
Summary
The article presents benchmark results from HomeSec-Bench, a comprehensive evaluation of AI models for security applications. The benchmark includes 96 tests across 15 suites covering tool use, security classification, and event deduplication. Results show cloud-based models like GPT-5.4 achieving the highest pass rates (97.9%), while local models like Qwen3.5-9B running on Apple Silicon perform competitively with 93.8% pass rate, within 4 points of the top cloud model. The benchmark compares performance and speed between cloud and local AI deployments for security tasks.
Key quotes
· 4 pulledQwen3.5-9B scores 93.8% on 96 real security AI tests — within 4 points of GPT-5.4 — running entirely on Apple Silicon
96-test evaluation across 15 suites covering tool use, security classification, event deduplication, and more
GPT-5.4 Cloud 94 2 97.9% 2m 22s
Qwen3.5-9B (Q4_K_M) Local 90 6 93.8% 5m 23s
You might also wanna read


Datacurve's DeepSWE Benchmark Shows GPT-5.5 Leading AI Coding Models with 70% Pass Rate
A new benchmark called DeepSWE, released by startup Datacurve, reveals significant performance differences among AI coding models that were
 share.transistor.fm·4d ago
share.transistor.fm·4d ago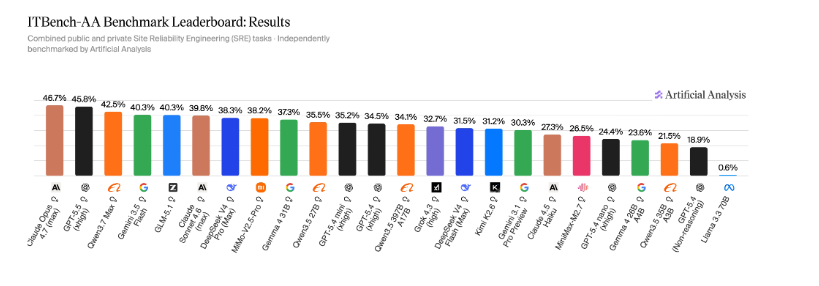
New ITBench-AA Benchmark Reveals AI Models Struggle with Enterprise SRE Tasks
ITBench-AA, a new benchmark developed by Artificial Analysis and IBM Research over six months, reveals that leading AI models like Claude Op