Datacurve's DeepSWE Benchmark Shows GPT-5.5 Leading AI Coding Models with 70% Pass Rate
The kind of bagel that ruins lesser bagels for you.
Summary
A new benchmark called DeepSWE, released by startup Datacurve, reveals significant performance differences among AI coding models that were previously hidden by flawed evaluation standards. OpenAI's GPT-5.5 leads with a 70% pass rate, while Anthropic's Claude Opus 4.7 trails at 54%, and mid-tier models like Claude Haiku 4.5 perform poorly. The report critiques the industry-standard SWE-Bench Pro for masking these divergences.
Key quotes
· 3 pulledA new benchmark released by startup Datacurve yesterday, DeepSWE, has revealed a significant divergence in the performance of frontier AI coding models, previously masked by flawed evaluation standards.
OpenAI's GPT-5.5 emerged as the dominant leader with a 70% pass rate, while competing models like Anthropic's Claude Opus 4.7 trailed at 54%.
The report critiques the industry-standard SWE-Bench Pro, identifying it as a flawed benchmark that masked true model capabilities.
You might also wanna read

Comparing GPT-5 and Claude 4 Sonnet for Agentic Coding Tasks
The article compares the performance of OpenAI's newly released GPT-5 and Claude 4 Sonnet in a complex agentic coding task using GitHub Copi
 elite-ai-assisted-coding.dev·9mo ago
elite-ai-assisted-coding.dev·9mo ago
SWE-bench Verified benchmark no longer accurately measures AI coding capabilities due to contamination
OpenAI's analysis finds that SWE-bench Verified, a benchmark for measuring AI coding capabilities, is increasingly contaminated and no longe
 openai.com·1mo ago
openai.com·1mo ago
OpenAI launches GPT-5.5 with improved coding and cross-tool capabilities
OpenAI has announced GPT-5.5, its latest AI model, just one month after releasing GPT-5.4. The company claims the new model excels at writin

GPT-5 Released for Developers: A State-of-the-Art Coding Model
GPT-5, the latest model from the API platform, is designed for coding and agentic tasks, excelling in benchmarks like SWE-bench Verified (74
 openai.com·9mo ago
openai.com·9mo ago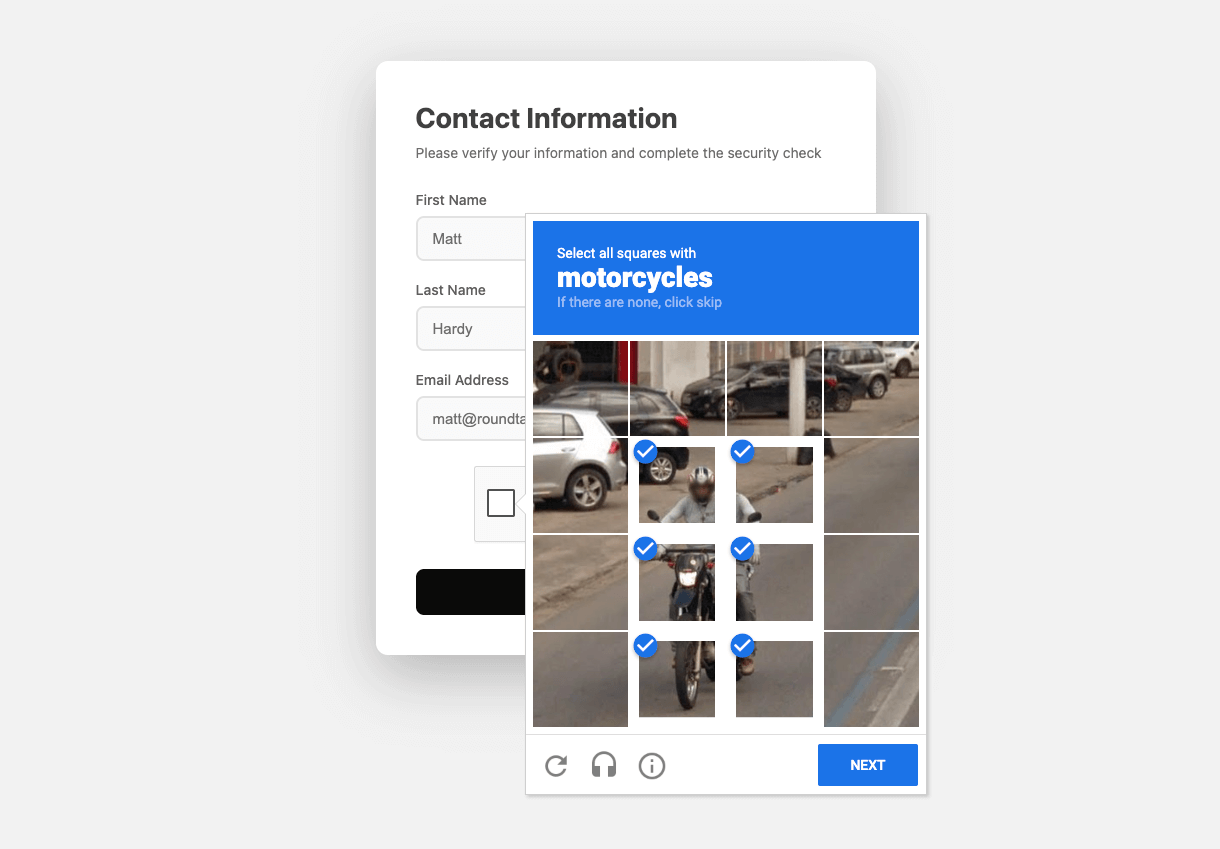
AI Model Performance Comparison: Claude Sonnet 4.5 Leads in CAPTCHA Solving Tests
The article presents a benchmarking study comparing three leading AI models—Claude Sonnet 4.5, Gemini 2.5 Pro, and GPT-5—on their ability to
 research.roundtable.ai·6mo ago
research.roundtable.ai·6mo ago
Microsoft Prioritizes Anthropic's Claude AI Over OpenAI's GPT-5 in Visual Studio Code Update
Microsoft is introducing automatic AI model selection in Visual Studio Code that will prioritize Anthropic's Claude Sonnet 4 over OpenAI's G