SWE-bench Verified benchmark no longer accurately measures AI coding capabilities due to contamination
By
kmdupree
A five-star bake. Worth schmearing, sharing, saving.
Summary
OpenAI's analysis finds that SWE-bench Verified, a benchmark for measuring AI coding capabilities, is increasingly contaminated and no longer accurately measures frontier coding progress. The benchmark suffers from test leakage (models trained on benchmark data) and flawed test cases that don't properly evaluate autonomous software engineering. The article recommends transitioning to SWE-bench Pro as a more robust alternative for measuring coding model performance.
Key quotes
· 5 pulledSince we first published SWE-bench Verified in August 2024, the industry has widely used it to measure the progress of models on autonomous software engineering tasks.
SWE-bench Verified provided a strong signal of capability progress and became a standard metric reported in frontier model releases.
Tracking and forecasting progress of these capabilities is also an important part of OpenAI's Preparedness Framework.
SWE-bench Verified is increasingly contaminated and mismeasures frontier coding progress.
Our analysis shows flawed tests and training leakage. We recommend SWE-bench Pro.
You might also wanna read


Datacurve's DeepSWE Benchmark Shows GPT-5.5 Leading AI Coding Models with 70% Pass Rate
A new benchmark called DeepSWE, released by startup Datacurve, reveals significant performance differences among AI coding models that were
 share.transistor.fm·4d ago
share.transistor.fm·4d ago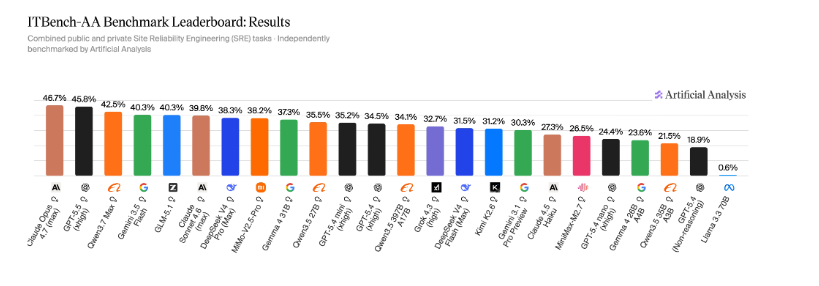
New ITBench-AA Benchmark Reveals AI Models Struggle with Enterprise SRE Tasks
ITBench-AA, a new benchmark developed by Artificial Analysis and IBM Research over six months, reveals that leading AI models like Claude Op
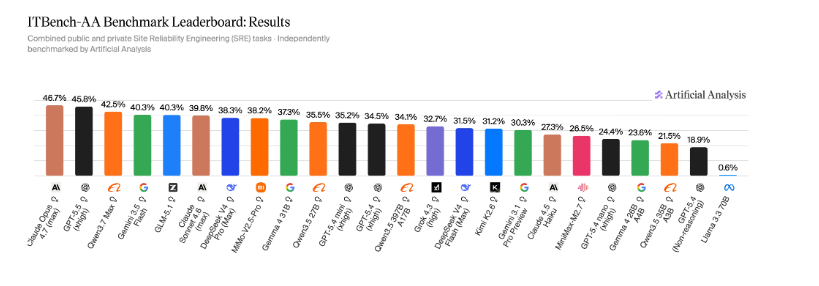
ITBench-AA Benchmark Launched: Frontier AI Models Score Below 50% on Enterprise IT Tasks
Artificial Analysis and IBM Software Innovation Lab have launched ITBench-AA, a new benchmark series evaluating AI models on agentic enterpr

Amazon's AI Chief Criticizes Benchmark Obsession, Emphasizes Real-World Utility
Amazon's AI chief Rohit Prasad argues that AI model benchmarks and leaderboards are misleading and don't reflect real-world utility. He crit

The Verification Crisis: How AI-Generated Code Is Reshaping Software Development
The article examines the rapid integration of AI in software development, highlighting staggering statistics: Cursor alone generates nearly
 dev.to·1d ago
dev.to·1d ago
AI code generation forces tech hiring managers to rethink software engineering interviews
The article examines how AI's ability to write code is disrupting software engineering hiring. With mass layoffs increasing competition and
 cnn.com·2d ago
cnn.com·2d ago