Why Current AI Agent Benchmarks Are Unreliable and Misleading
By
neehao
The bagel they save for the regulars. Don't skim, savour.
Summary
The article argues that current AI agent benchmarks are fundamentally flawed and unreliable. Unlike traditional AI benchmarks, agent benchmarks require complex simulators and lack clear gold-standard labels, making them harder to validate. The author contends that many existing benchmarks suffer from design issues, poor reproducibility, and fail to measure what truly matters for real-world AI agent performance. This undermines their utility for guiding research and industry development.
Key quotes
· 3 pulledThese AI agent benchmarks are significantly more complex than traditional AI benchmarks in task formulation (e.g., often requiring a simulator of realistic scenarios) and evaluation (e.g., no gold label), requiring greater effort to ensure their reliability.
Unfortunately, many current AI agent benchmarks are broken.
Benchmarks are foundational to evaluating the strengths and limitations of AI systems, guiding both research and industry development.
You might also wanna read

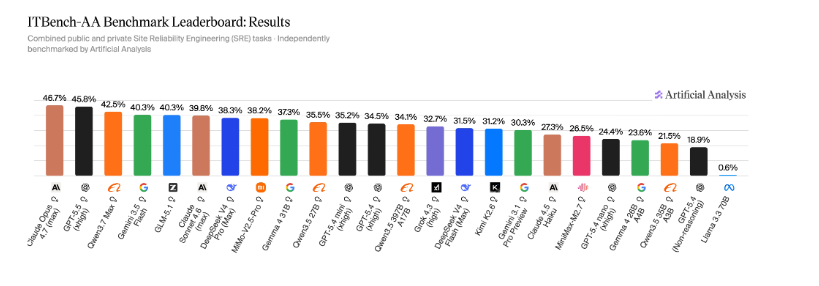
New ITBench-AA Benchmark Reveals AI Models Struggle with Enterprise SRE Tasks
ITBench-AA, a new benchmark developed by Artificial Analysis and IBM Research over six months, reveals that leading AI models like Claude Op
Web Bench: A Comprehensive Benchmark for AI Browser Agent Performance
Web Bench is a new benchmark platform designed to evaluate and compare AI browser agents' performance in web navigation tasks. It provides c
 Product Hunt·1y ago
Product Hunt·1y ago
Amazon's AI Chief Criticizes Benchmark Obsession, Emphasizes Real-World Utility
Amazon's AI chief Rohit Prasad argues that AI model benchmarks and leaderboards are misleading and don't reflect real-world utility. He crit
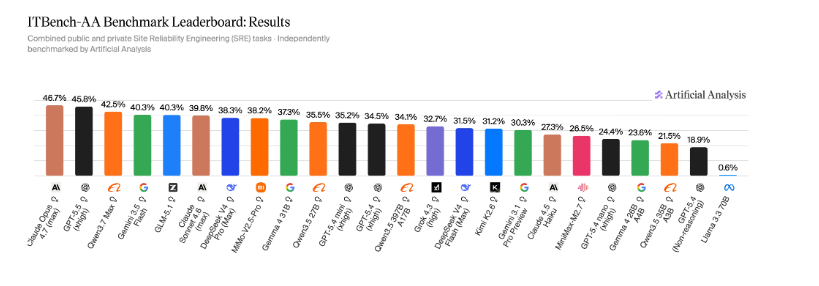
ITBench-AA Benchmark Launched: Frontier AI Models Score Below 50% on Enterprise IT Tasks
Artificial Analysis and IBM Software Innovation Lab have launched ITBench-AA, a new benchmark series evaluating AI models on agentic enterpr
Scorecard: Platform for Evaluating and Optimizing AI Agents in High-Stakes Applications
The CEO of Scorecard shares a cautionary tale about nearly shipping a dangerous AI agent for doctors that confused pediatric and adult dosin
Product Hunt·7mo ago
Scorecard CEO warns of AI agent dangers in high-stakes domains, offers evaluation platform
Darius, CEO of Scorecard, shares a cautionary tale about building AI agents in high-stakes domains. He describes how his EMR agent for docto
Product Hunt·7mo ago