TurboQuant: A compression method to reduce AI agent memory usage by 5-8x without quality loss
By
StartupHub.ai
Summary
Shashi Jagtap, founder of Superagentic AI, introduces TurboQuant, a novel compression method for AI agent retrieval systems. The approach targets the memory and computational bottlenecks of large language models, specifically the KV cache and vector embeddings. TurboQuant claims to reduce memory usage by 5-8x without quality degradation, overcoming the traditional trade-off between compression and performance that often requires retraining or sacrifices accuracy.
Source

 bskyTurboQuant: A compression method to reduce AI agent memory usage by 5-8x without quality lossstartuphub.ai
bskyTurboQuant: A compression method to reduce AI agent memory usage by 5-8x without quality lossstartuphub.aiKey quotes
· 2 pulledThe core problem addressed by TurboQuant lies in the substantial memory footprint and computational cost associated with large language models (LLMs) and their retrieval mechanisms, particularly the KV cache and vector embeddings.
Jagtap explained how traditional methods of compression often lead to a drop in quality or require extensive retraining, a trade-off that TurboQuant aims to overcome.
You might also wanna read


TurboQuant: AI Efficiency Technology Using Extreme Compression for High-Dimensional Vectors
The article discusses TurboQuant, a new AI efficiency technology that addresses the memory bottleneck problem in AI models caused by high-di
 research.google·3mo ago
research.google·3mo ago
TurboQuant: Compressing AI Vectors to 2-4 Bits Using Random Rotations
TurboQuant is a novel compression technique for AI vectors (KV caches, embeddings, attention keys) that compresses each coordinate to 2-4 bi
arkaung.github.io·2mo ago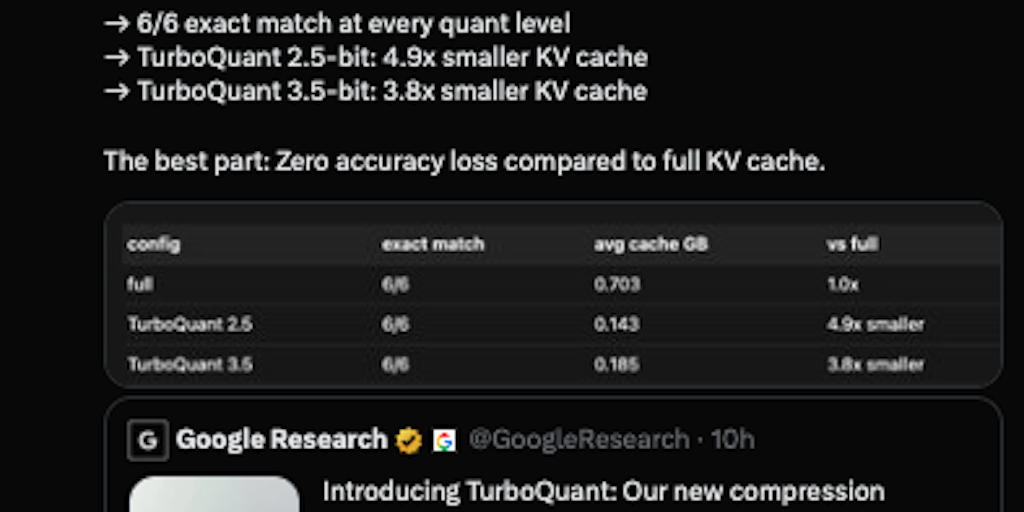
Google Introduces TurboQuant: Advanced LLM Compression Algorithm for Efficient AI Model Deployment
Google has developed TurboQuant, a new LLM compression algorithm that uses advanced theoretically grounded quantization techniques to enable
 Product Hunt·3mo ago
Product Hunt·3mo ago
Sequential KV Cache Compression Using Probabilistic Language Tries and Predictive Delta Coding
This research paper introduces a novel two-layer architecture for compressing transformer key-value (KV) caches as sequences rather than ind

Expected Attention: KV Cache Compression Method for Efficient LLM Inference
This research paper introduces Expected Attention, a training-free method for compressing Key-Value (KV) cache in large language models to r

Attention Matching: Fast KV Cache Compaction for Language Models
This article presents a new approach called Attention Matching for fast key-value (KV) cache compaction in language models. Traditional meth
Comments
Sign in to join the conversation.
No comments yet. Be the first.