TurboQuant: Compressing AI Vectors to 2-4 Bits Using Random Rotations
By
kweezar
1mo ago· 17 min readenInsight
100/100
Golden Brown
Bagelometer↗
Sesame, salt, and substance. A flagship bake.
Score100TypeanalysisSentimentneutral
Summary
TurboQuant is a novel compression technique for AI vectors (KV caches, embeddings, attention keys) that compresses each coordinate to 2-4 bits per number without losing accuracy. The key insight is that in high dimensions, a random rotation transforms input vectors into ones with known coordinate distributions, enabling provably near-optimal distortion with no memory overhead for scale factors and no need for training or calibration. The article provides a first-principles walkthrough of the mathematical foundations behind this approach.
Key quotes
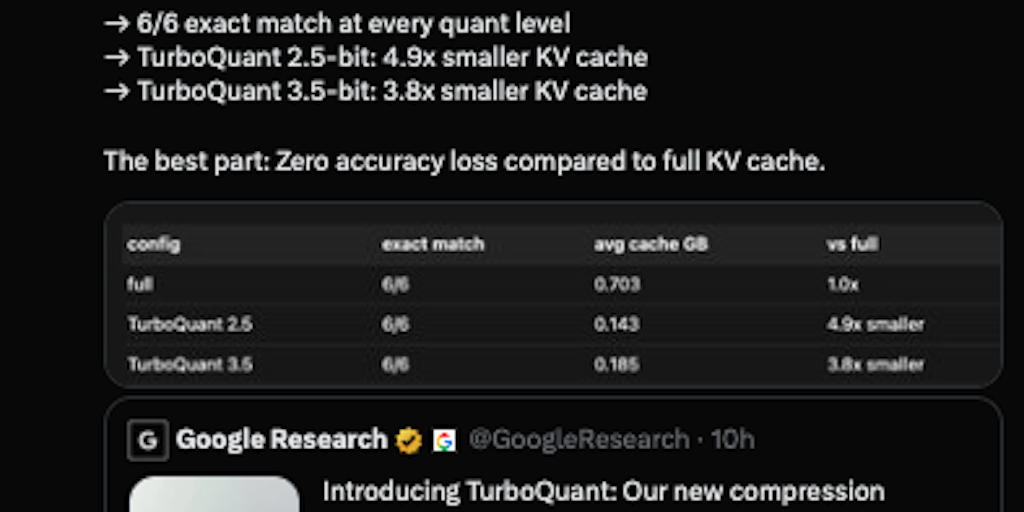
· 3 pulledTurboQuant compresses each coordinate of these vectors to 2–4 bits with provably near-optimal distortion, no memory overhead for scale factors, and no training or calibration.
The single load-bearing idea: in high dimensions, a random rotation turns every input vector into one whose coordinates follow a known distribution.
Modern language models store large tables of high-dimensional vectors: KV caches, embeddings, attention keys.
TurboQuant: A First-Principles Walkthrough