Google Introduces TurboQuant: Advanced LLM Compression Algorithm for Efficient AI Model Deployment
A set of advanced theoretically grounded quantization algorithms that enable massive compression for large language models and vector search engines.
Read the full articleYou might also wanna read
Google TurboQuant Cuts LLM Memory by 6x
Google's TurboQuant compresses LLM key-value cache to 3 bits with zero accuracy loss. Complete guide to what it means for local AI developme

Google's TurboQuant Compresses LLM KV Cache Memory by 6x Without Accuracy Loss
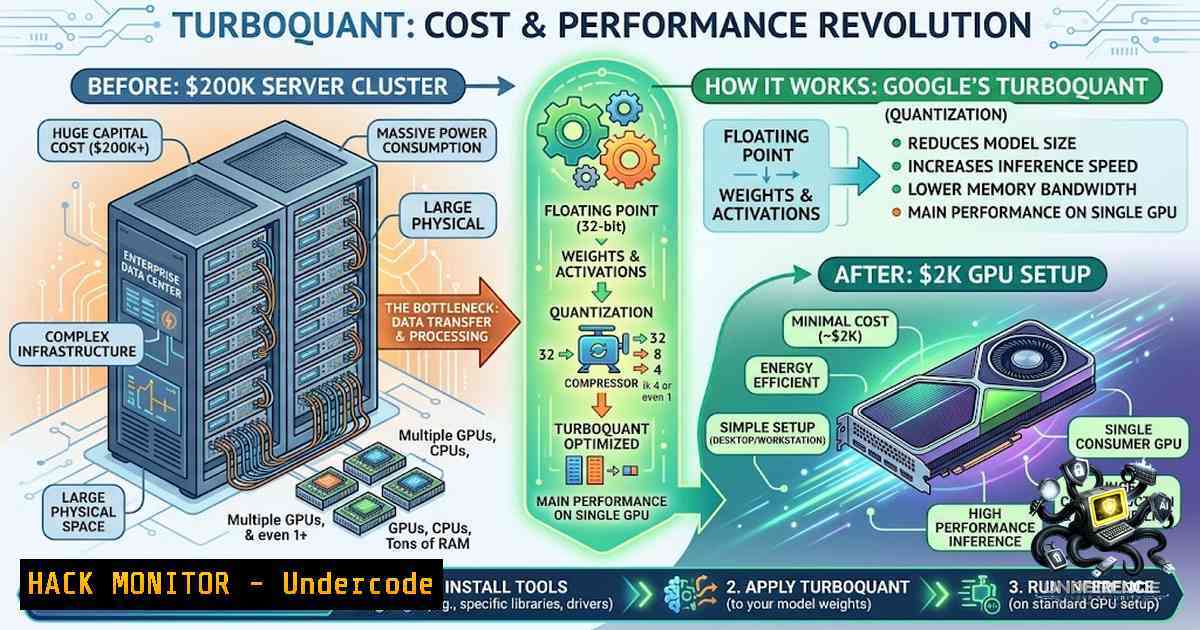
Google’s TurboQuant Just Turned Your 00K Server Cluster Into a K GPU Setup — Here’s How to Deploy It Today - "Undercode Testing": Monitor ha
 undercodetesting.com·24d ago
undercodetesting.com·24d ago
TurboQuant: A compression method to reduce AI agent memory usage by 5-8x without quality loss
Shashi Jagtap of Superagentic AI introduces TurboQuant, a method to compress AI agent memory and embeddings, reducing usage by 5-8x with no
 startuphub.ai·18d ago
startuphub.ai·18d ago
TurboQuant: AI Efficiency Technology Using Extreme Compression for High-Dimensional Vectors
Vectors are the fundamental way AI models understand and process information. Small vectors describe simple attributes, such as a point in a
 research.google·3mo ago
research.google·3mo ago
TurboQuant: Compressing AI Vectors to 2-4 Bits Using Random Rotations
TurboQuant: A First-Principles Walkthrough
arkaung.github.io·2mo agoGoogle's TurboQuant KV Cache Tech Gains Community Traction Despite No Official Code
TurboQuant, a training-free KV cache compression algorithm from Google Research and Google DeepMind, was accepted at ICLR 2026 with claims o
Comments
Sign in to join the conversation.
No comments yet. Be the first.