TurboQuant: AI Efficiency Technology Using Extreme Compression for High-Dimensional Vectors
By
ray__
Slow-proofed and worth the wait. Worth its weight in flour.
Summary
The article discusses TurboQuant, a new AI efficiency technology that addresses the memory bottleneck problem in AI models caused by high-dimensional vectors. It explains how vectors are fundamental to AI processing, with high-dimensional vectors capturing complex information but consuming excessive memory. The technology focuses on extreme compression techniques to reduce memory usage while maintaining performance, potentially redefining AI efficiency by optimizing the key-value cache system that stores frequently used information for rapid retrieval.
Key quotes
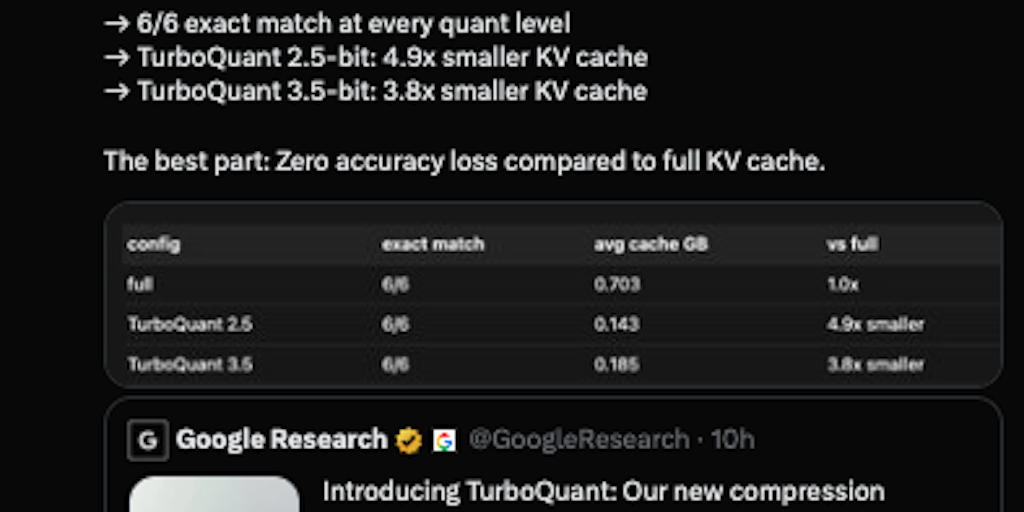
· 4 pulledVectors are the fundamental way AI models understand and process information.
High-dimensional vectors are incredibly powerful, but they also consume vast amounts of memory, leading to bottlenecks in the key-value cache.
High-dimensional vectors capture complex information such as the features of an image, the meaning of a word, or the properties of a dataset.
The key-value cache is a high-speed 'digital cheat sheet' that stores frequently used information under simple labels so a computer can retrieve it instantly without having to search through a slow, massive database.
You might also wanna read

Google Introduces TurboQuant: Advanced LLM Compression Algorithm for Efficient AI Model Deployment
Google has developed TurboQuant, a new LLM compression algorithm that uses advanced theoretically grounded quantization techniques to enable
 Product Hunt·2mo ago
Product Hunt·2mo ago
Actian VectorAI DB: A portable vector database for local AI deployment across edge, on-prem, and hybrid systems
Actian VectorAI DB is a portable vector database designed for AI applications that can run locally across embedded, edge, on-prem, and hybri
Product Hunt·2mo ago