Prompt Injection Explained as a Role Confusion Problem in LLMs
Summary
This paper presents a theory of prompt injection attacks on LLMs, arguing that the root cause is a fundamental flaw in how models perceive roles — they cannot distinguish between their own thoughts and injected content. The authors demonstrate that LLMs identify roles by writing style rather than explicit tags, and exploit this with a technique called CoT Forgery, where fake reasoning is injected that models mistake for their own thoughts. The work connects prompt injection to mechanistic interpretability results, predicts when attacks succeed, and proposes a new research agenda for a "science of roles" in LLMs.
Source
 bskyPrompt Injection Explained as a Role Confusion Problem in LLMsrole-confusion.github.io
bskyPrompt Injection Explained as a Role Confusion Problem in LLMsrole-confusion.github.ioKey quotes
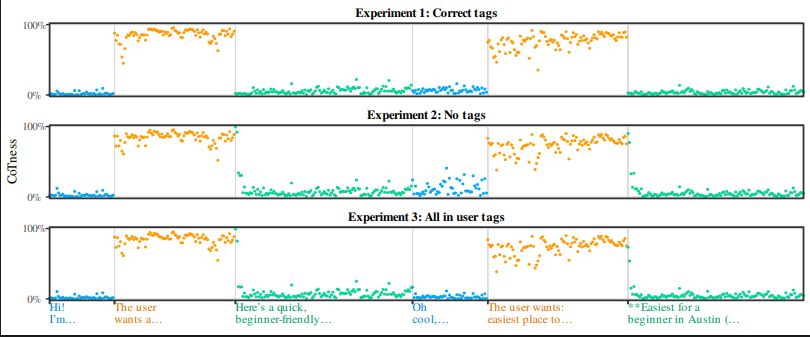
· 3 pulledWe show prompt injections are driven by a flaw in how LLMs perceive roles.
LLMs can't tell who's speaking. We show they identify roles by writing style, not tags.
We exploit this with CoT Forgery, injecting fake reasoning that models mistake for their own thoughts.
You might also wanna read

Prompt Injection Explained as Role Confusion in LLMs
This article presents a theory that prompt injection attacks on LLMs succeed because models identify roles (like "user" vs "assistant") thro
role-confusion.github.io·11d ago
New Research Papers Address LLM Security and Prompt Injection Vulnerabilities
The article discusses two new research papers on LLM security and prompt injection vulnerabilities. The first paper, 'Agents Rule of Two: A
Design Patterns for Securing LLM Agents Against Prompt Injections

Understanding "Disregard that!" Attacks: The Prompt Injection Vulnerability in LLMs
The article discusses the security vulnerability in Large Language Models (LLMs) known as "prompt injection," which the author refers to as
 calpaterson.com·3mo ago
calpaterson.com·3mo ago
Study Reveals Domain-Camouflaged Injection Attacks Bypass LLM Detection Systems
This research paper identifies a critical vulnerability in injection detectors used to protect LLM agents. The authors demonstrate that when

Security Risks of Malicious Backdoors in Large Language Models
The article explores the security risks associated with Large Language Models (LLMs), particularly the potential for embedding malicious bac
 pub.aimind.so·10mo ago
pub.aimind.so·10mo ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.