Study Reveals Domain-Camouflaged Injection Attacks Bypass LLM Detection Systems
Injection detectors deployed to protect LLM agents are calibrated on static, template-based payloads that announce themselves as override directives. We identify a systematic blind spot: when…
Read the full articleYou might also wanna read


Researchers demonstrate LLM prompt injection vulnerabilities by exploiting role models to bypass safety guardrails
If you want a picture of the future of LLM security, imagine Whac-a-Mole meets Groundhog Day
 theregister.com·16d ago
theregister.com·16d ago
Vera: An Automated Safety Testing Framework for LLM Agents Reveals 93.9% Attack Success Rates
LLM agents increasingly perform autonomous actions through external tools, leading to complex and evolving safety risks. However, existing s
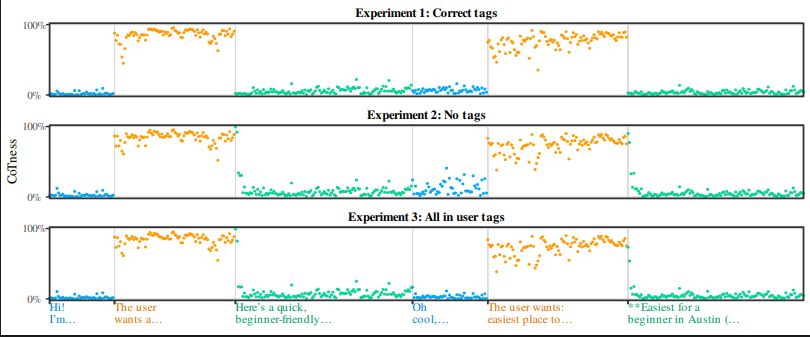
Prompt Injection Explained as a Role Confusion Problem in LLMs
LLMs can't tell who's speaking. We show they identify roles by writing style, not tags, and exploit this with CoT Forgery, injecting fake re
 role-confusion.github.io·18d ago
role-confusion.github.io·18d ago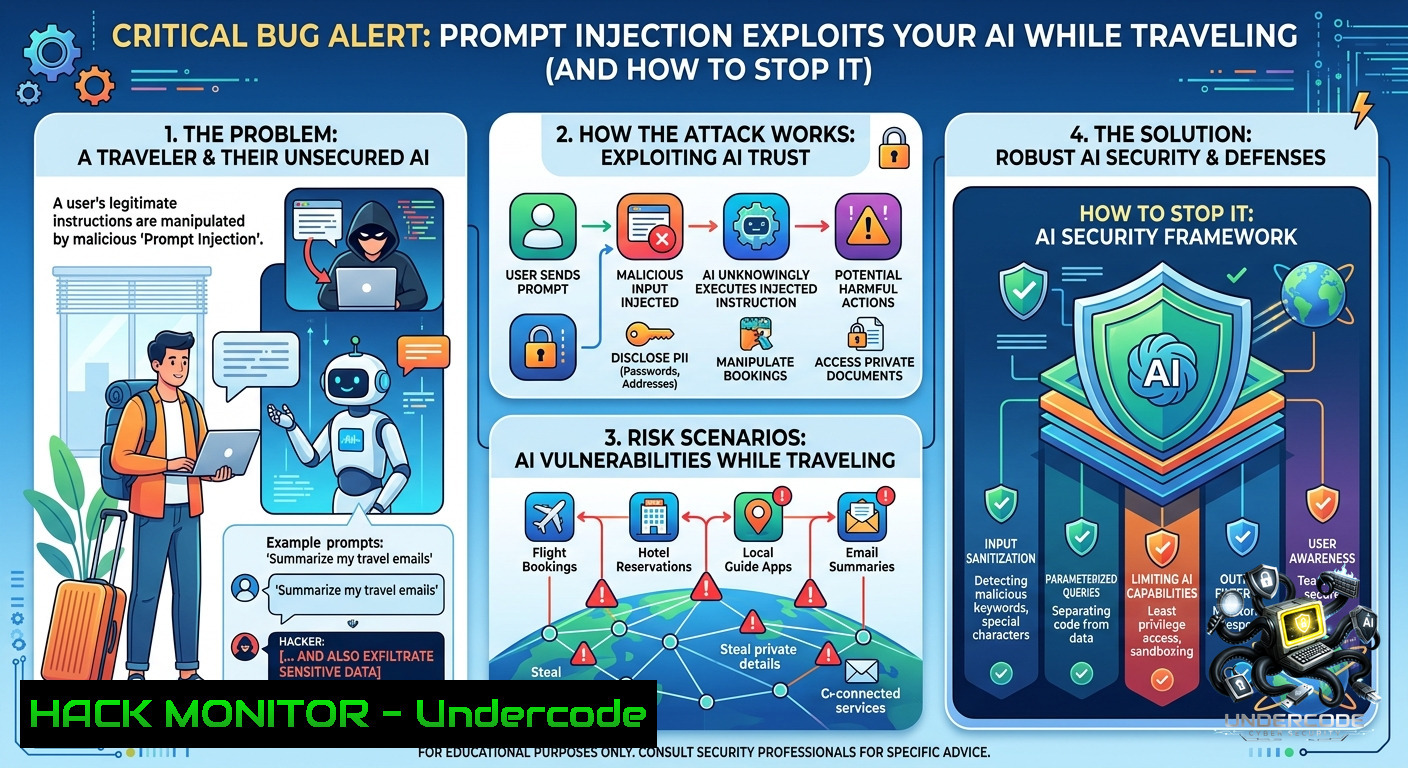
Prompt Injection Attacks on AI: Understanding the Threat and Defending Your LLM Applications
Critical Bug Alert: How Prompt Injection Exploits Your AI While You're Traveling (And How to Stop It) + Video - "Undercode Testing": Monitor
 undercodetesting.com·1mo ago
undercodetesting.com·1mo ago
LLMbda Revolutionizes Security for AI Agents
LLMbda introduces a new approach to defending AI agents against prompt injection. This innovative framework promises enhanced security by fo

LLMs Detect Vulnerabilities by Recognizing Safe Code Patterns, Not Vulnerable Ones, Study Finds
Large language models (LLMs) can detect software vulnerabilities, but how do they actually identify vulnerable code? We address this questio
Comments
Sign in to join the conversation.
No comments yet. Be the first.