New Research Papers Address LLM Security and Prompt Injection Vulnerabilities
Two interesting new papers regarding LLM security and prompt injection came to my attention this weekend. Agents Rule of Two: A Practical Approach to AI Agent Security The first is …
Read the full articleYou might also wanna read

Prompt Injection Attacks on AI: Understanding the Threat and Defending Your LLM Applications
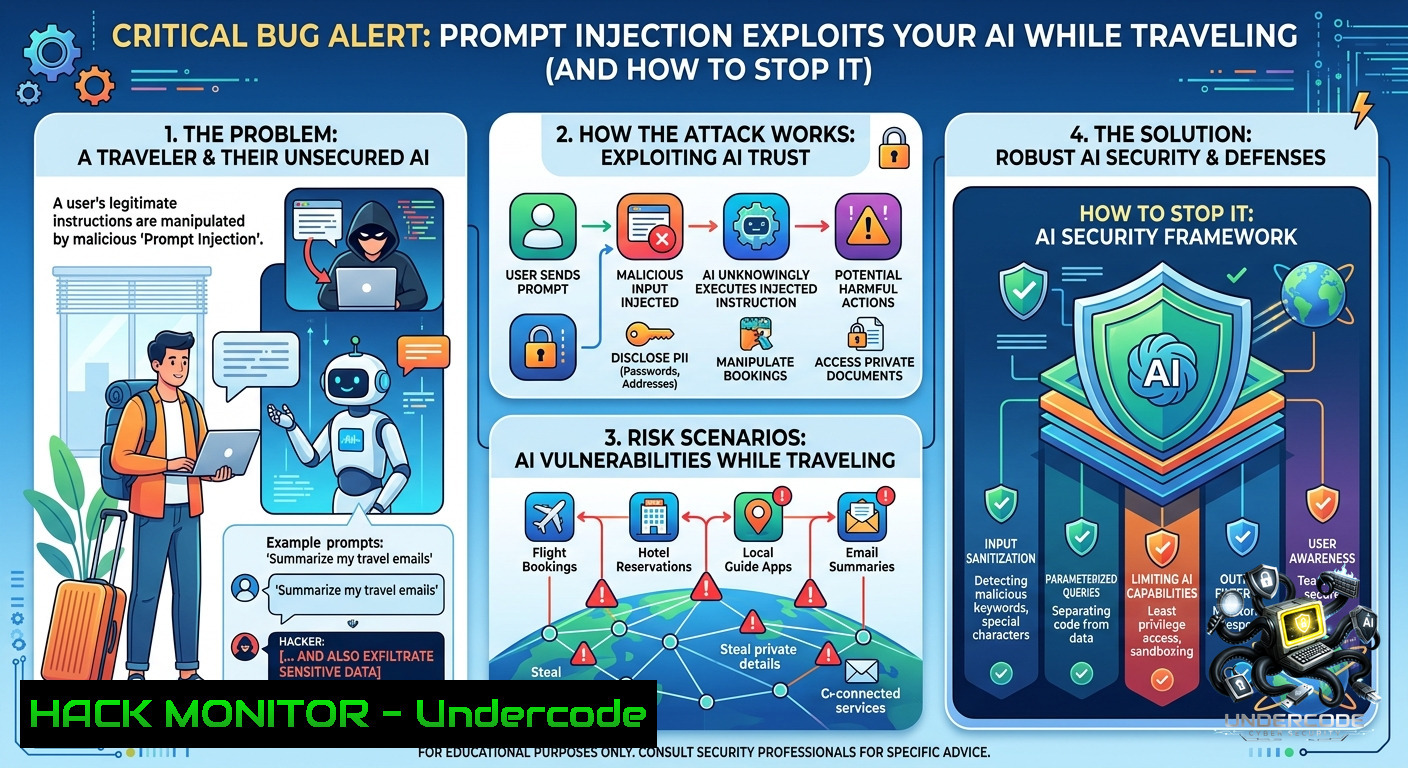
Critical Bug Alert: How Prompt Injection Exploits Your AI While You're Traveling (And How to Stop It) + Video - "Undercode Testing": Monitor
 undercodetesting.com·1mo ago
undercodetesting.com·1mo ago
LLMbda Revolutionizes Security for AI Agents
LLMbda introduces a new approach to defending AI agents against prompt injection. This innovative framework promises enhanced security by fo

Researchers demonstrate LLM prompt injection vulnerabilities by exploiting role models to bypass safety guardrails
If you want a picture of the future of LLM security, imagine Whac-a-Mole meets Groundhog Day
 theregister.com·16d ago
theregister.com·16d ago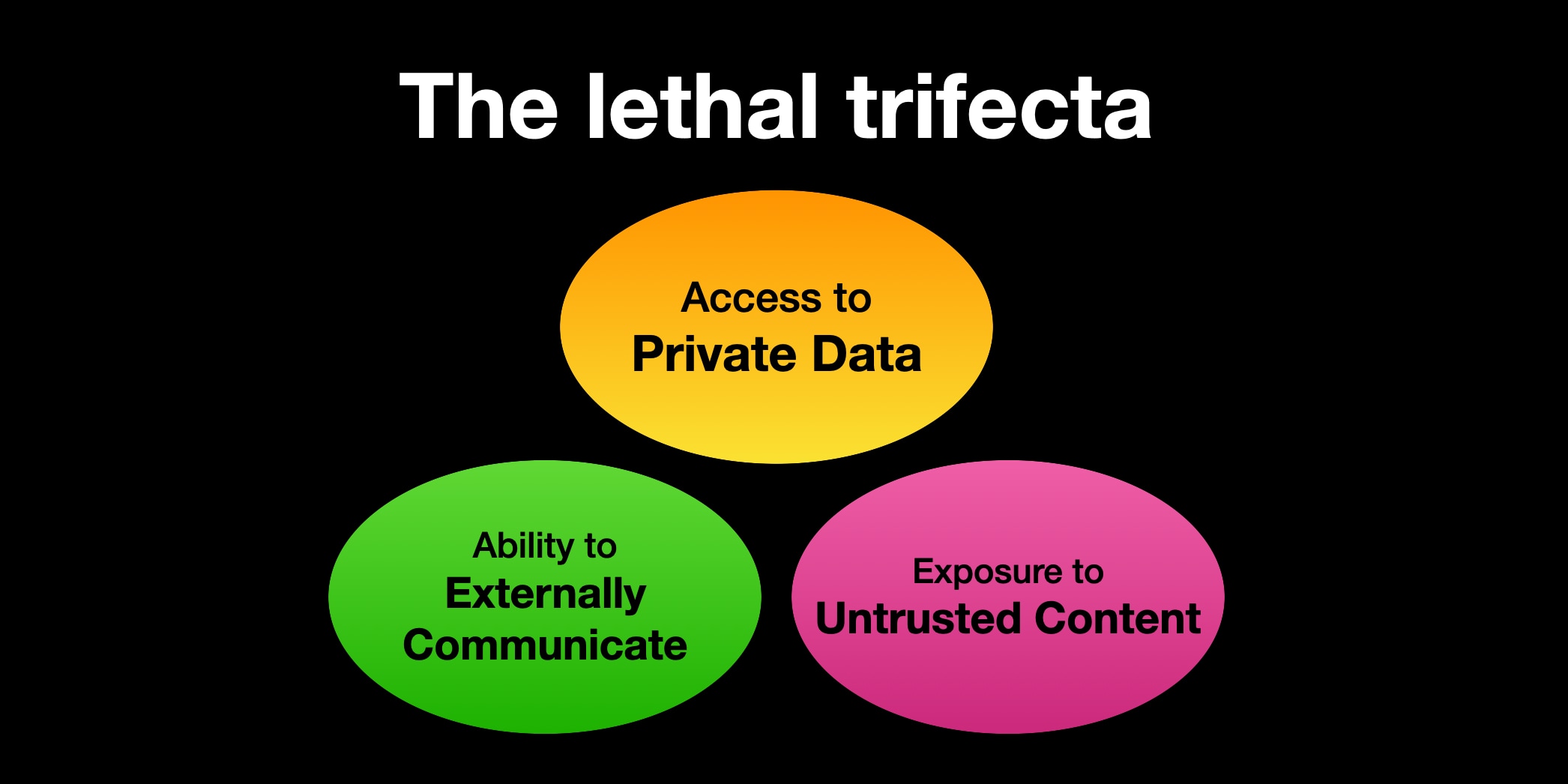
The security risk of combining private data access, untrusted content, and external communication in AI agents
If you are a user of LLM systems that use tools (you can call them “AI agents” if you like) it is critically important that you understand t

An investigation into code injection vulnerabilities caused by generative AI
This article looks at the potential security implications of large language models (LLMs), a text-producing form of generative AI.
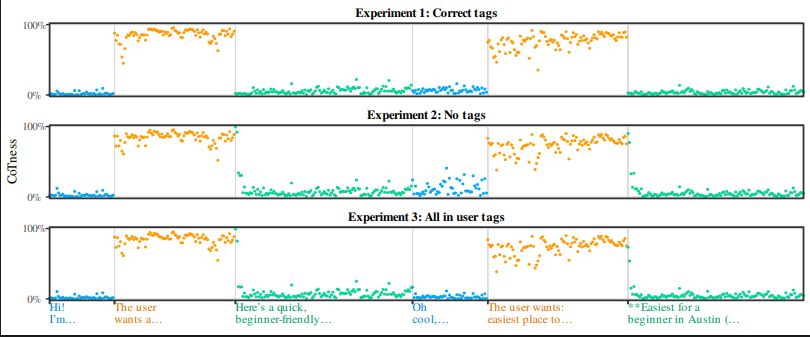
Prompt Injection Explained as a Role Confusion Problem in LLMs
LLMs can't tell who's speaking. We show they identify roles by writing style, not tags, and exploit this with CoT Forgery, injecting fake re
 role-confusion.github.io·18d ago
role-confusion.github.io·18d ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.