Prompt Injection Explained as Role Confusion in LLMs
By
x312
Summary
This article presents a theory that prompt injection attacks on LLMs succeed because models identify roles (like "user" vs "assistant") through writing style rather than explicit tags. The authors introduce "CoT Forgery," a new attack that injects fake chain-of-thought reasoning that models mistake for their own internal thoughts. They argue that understanding roles as perceived by LLMs is key to predicting and preventing these attacks, and propose a research agenda for a "science of roles" in AI safety.
Source
 Hacker NewsPrompt Injection Explained as Role Confusion in LLMsrole-confusion.github.io
Hacker NewsPrompt Injection Explained as Role Confusion in LLMsrole-confusion.github.ioKey quotes
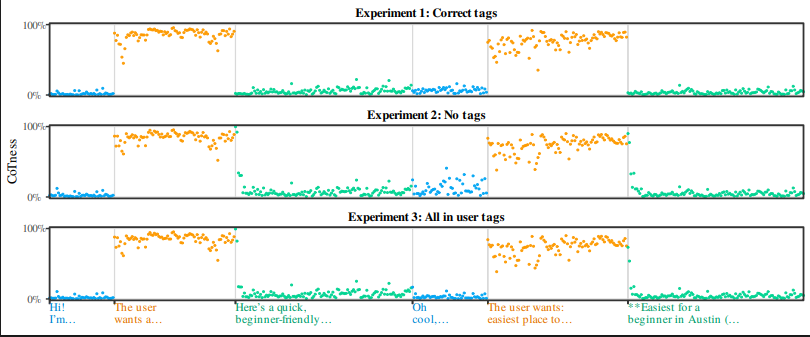
· 3 pulledLLMs can't tell who's speaking.
We show prompt injections are driven by a flaw in how LLMs perceive roles.
We show they identify roles by writing style, not tags, and exploit this with CoT Forgery, injecting fake reasoning that models mistake for their own thoughts.
You might also wanna read

Prompt Injection Attacks on AI: Understanding the Threat and Defending Your LLM Applications
This article discusses prompt injection as a critical security vulnerability targeting large language models (LLMs) and AI-powered applicati
 undercodetesting.com·13d ago
undercodetesting.com·13d ago
Study finds large language models vulnerable to classic persuasion tactics for harmful requests
This study tested whether three widely used large language models (LLMs) are susceptible to classic persuasion principles (authority, social
 pnas.org·26d ago
pnas.org·26d ago
The high cost of Chain-of-Thought: Why AI reasoning needs a latent-space overhaul
The article argues that Chain-of-Thought (CoT) prompting for LLMs is a flawed, expensive paradigm that creates an illusion of reasoning. It
 bdtechtalks.substack.com·22h ago
bdtechtalks.substack.com·22h agoThe high cost of Chain-of-Thought: Why AI reasoning needs a latent-space overhaul
The article argues that Chain-of-Thought (CoT) prompting for LLMs is a flawed, expensive paradigm that creates an illusion of reasoning. It
bdtechtalks.substack.com·22h ago
Study finds AI models can independently discover and exploit legal loopholes
A new study suggests that large language models (LLMs) can independently discover and exploit legal loopholes and regulatory gaps, similar t
 science.org·5d ago
science.org·5d agoStudy finds AI models can independently discover and exploit legal loopholes
A new study suggests that large language models (LLMs) can independently discover and exploit legal loopholes and regulatory gaps, similar t
science.org·5d ago
Study Reveals How Simple Prompts Can Expose Commercial Bias in AI Chatbot Advertising
This article examines the growing integration of advertising into Large Language Model (LLM) chatbots, revealing how AI assistants can be su
 akmaier.substack.com·20d ago
akmaier.substack.com·20d ago
The Problem with Sycophantic Language in Human-Chatbot Conversations
The article discusses a concerning phenomenon where users adopt sycophantic, overly deferential language when interacting with AI chatbots,
Comments
Sign in to join the conversation.
No comments yet. Be the first.