Prompt Injection Attacks on AI: Understanding the Threat and Defending Your LLM Applications
By
HackMoN Ai
The kind of bagel that ruins lesser bagels for you.
Summary
This article discusses prompt injection as a critical security vulnerability targeting large language models (LLMs) and AI-powered applications. It explains how adversaries craft malicious inputs to override system instructions, and highlights that security teams are especially vulnerable when distracted (e.g., while traveling). The article covers both offensive testing methods and defensive hardening strategies for DevSecOps pipelines, aiming to educate readers on identifying and mitigating prompt injection attacks.
Key quotes
· 3 pulledPrompt injection is a rapidly growing attack vector targeting large language models (LLMs) and AI‑powered applications, where adversaries craft malicious inputs to override original system instructions.
When security teams are distracted—such as while traveling—these critical bugs can slip through monitoring, allowing attackers to exfiltrate data, bypass content filters, or execute unauthorized actions.
Understanding both offensive testing and defensive hardening is essential for any modern DevSecOps pipeline.
You might also wanna read


Understanding "Disregard that!" Attacks: The Prompt Injection Vulnerability in LLMs
The article discusses the security vulnerability in Large Language Models (LLMs) known as "prompt injection," which the author refers to as
 calpaterson.com·2mo ago
calpaterson.com·2mo ago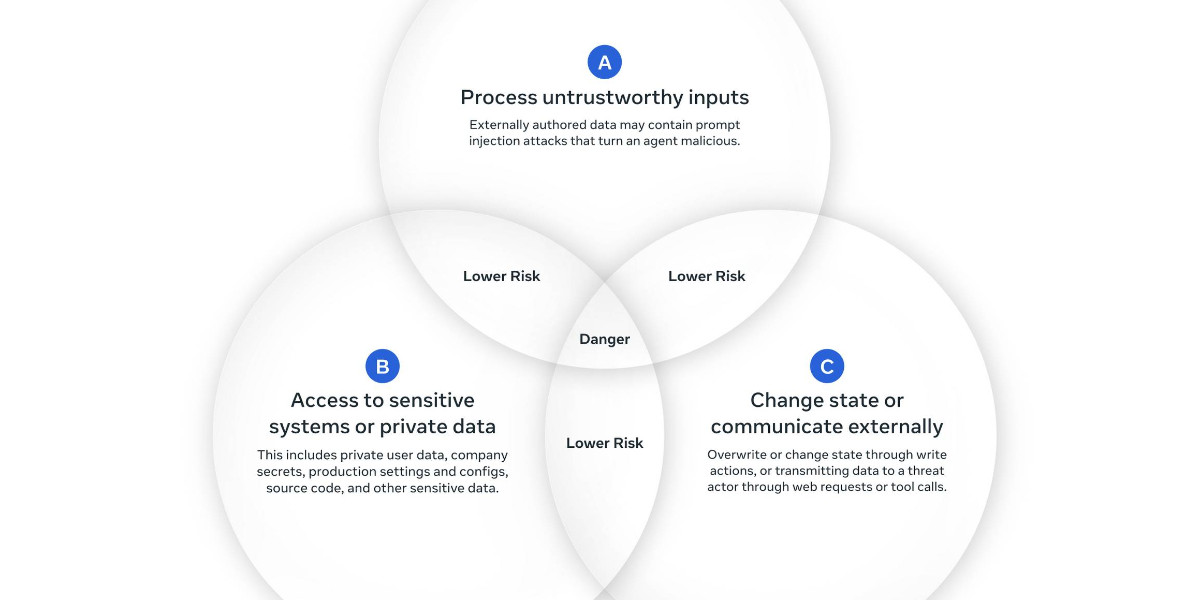
New Research Papers Address LLM Security and Prompt Injection Vulnerabilities
The article discusses two new research papers on LLM security and prompt injection vulnerabilities. The first paper, 'Agents Rule of Two: A

AI Coding Agent Security: Prompt Injection Attacks and Vulnerabilities
The article discusses critical security vulnerabilities in AI coding agents, specifically focusing on prompt injection attacks. It details r
 openguard.sh·2mo ago
openguard.sh·2mo agoDesign Patterns for Securing LLM Agents Against Prompt Injections

AI Security Vulnerability: Autonomous Vehicles and Drones Susceptible to Environmental Prompt Injection Attacks via Road Signs
Researchers have demonstrated a new class of AI security vulnerability called 'environmental indirect prompt injection attacks' where autono
 theregister.com·4mo ago
theregister.com·4mo ago
Security Risks of Malicious Backdoors in Large Language Models
The article explores the security risks associated with Large Language Models (LLMs), particularly the potential for embedding malicious bac
 pub.aimind.so·10mo ago
pub.aimind.so·10mo ago