PHOTON: Hierarchical Autoregressive Model for Efficient Language Generation
By
PaulHoule
A good honest bake. Not flashy, but you'll finish the whole bagel.
Summary
PHOTON is a new hierarchical autoregressive model architecture that addresses the memory and latency limitations of traditional Transformers in language generation. Unlike Transformers that scan tokens horizontally, PHOTON uses a vertical, multi-resolution approach with hierarchical latent streams. It features a bottom-up encoder that compresses tokens into low-rate contextual states and lightweight top-down decoders for token reconstruction. This architecture significantly reduces KV-cache traffic during decoding, achieving up to 1000x higher throughput per unit memory while maintaining competitive quality, especially in long-context and multi-query tasks.
Key quotes
· 4 pulledTransformers operate as horizontal token-by-token scanners; at each generation step, the model attends to an ever-growing sequence of token-level states.
We propose Parallel Hierarchical Operation for Top-down Networks (PHOTON), a hierarchical autoregressive model that replaces flat scanning with vertical, multi-resolution context access.
PHOTON maintains a hierarchy of latent streams: a bottom-up encoder progressively compresses tokens into low-rate contextual states, while lightweight top-down decoders reconstruct fine-grained token representations.
This reduces decode-time KV-cache traffic, yielding up to $10^{3} imes$ higher throughput per unit memory.
You might also wanna read


Chroma Context-1: A 20B Parameter Agentic Search Model for Multi-Hop Retrieval
Chroma Context-1 is a 20B parameter agentic search model designed to improve retrieval-augmented generation (RAG) systems. Unlike traditiona
 trychroma.com·2mo ago
trychroma.com·2mo ago
ATLAS: Adaptive Test-time Learning System Achieves 74.6% Code Benchmark Performance with Frozen 14B Model
ATLAS (Adaptive Test-time Learning and Autonomous Specialization) is a system that wraps a frozen smaller language model (14B parameters) wi
 github.com·2mo ago
github.com·2mo ago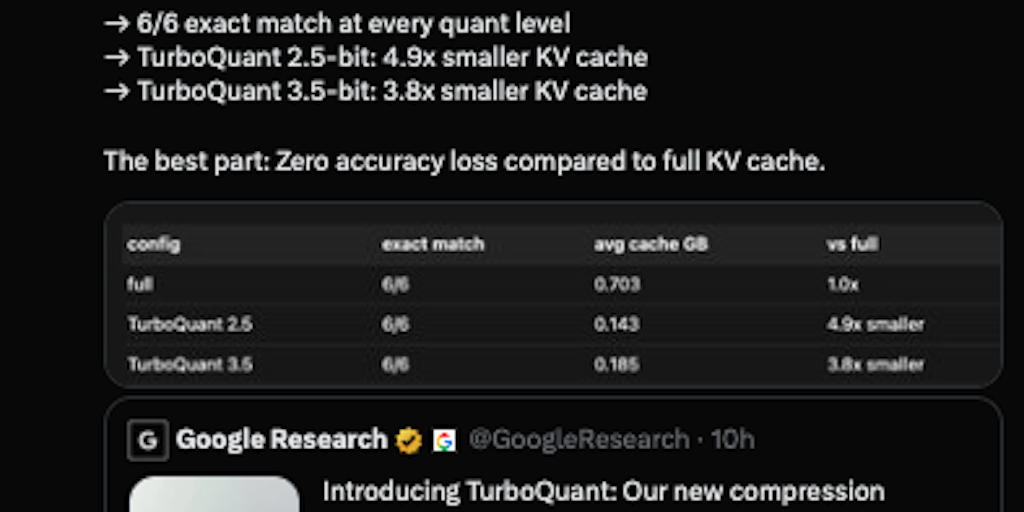
Google Introduces TurboQuant: Advanced LLM Compression Algorithm for Efficient AI Model Deployment
Google has developed TurboQuant, a new LLM compression algorithm that uses advanced theoretically grounded quantization techniques to enable
 Product Hunt·2mo ago
Product Hunt·2mo ago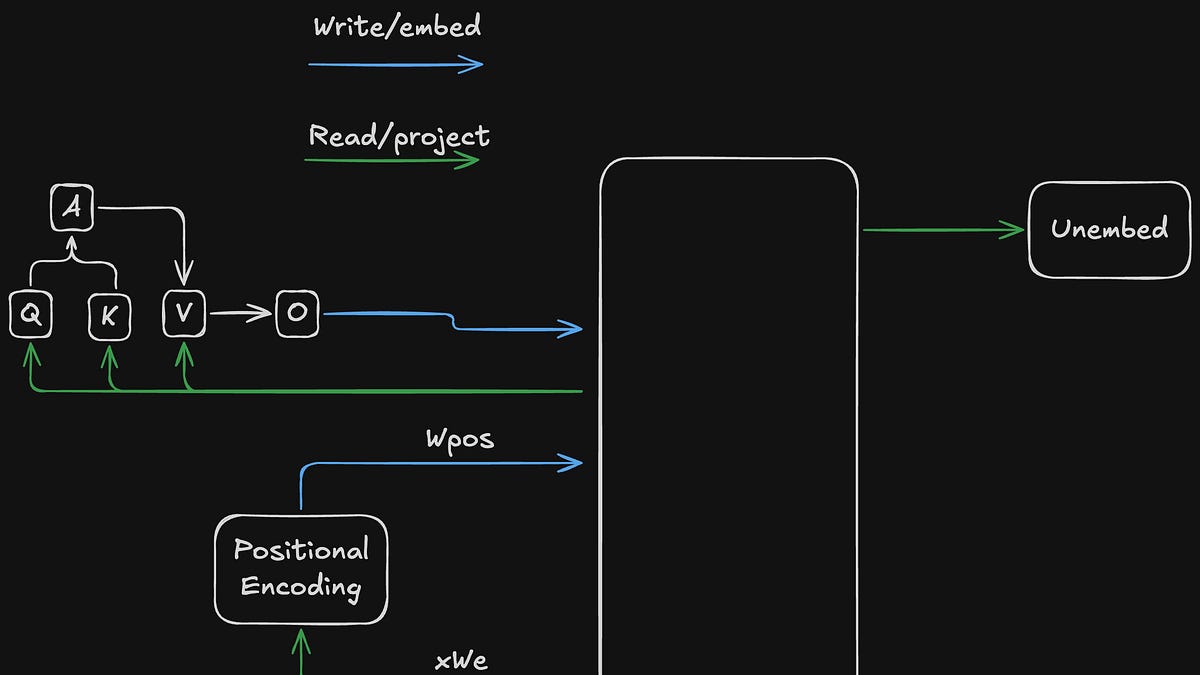
Understanding Transformer Circuits: A Mechanistic Interpretability Perspective
This article explores mechanistic interpretability of transformer neural networks, focusing on understanding how transformers work mathemati
 connorjdavis.com·2mo ago
connorjdavis.com·2mo ago
Achieving Top Position on HuggingFace LLM Leaderboard Through Model Analysis and Optimization Techniques
The article describes how the author achieved the #1 position on the HuggingFace Open LLM Leaderboard without training or modifying any mode
 dnhkng.github.io·2mo ago
dnhkng.github.io·2mo ago
Phi-4 Reasoning: Small Open-Weight AI Models with Strong Math and Science Capabilities
Phi-4 Reasoning is a small open-weight language model (3.8B/14B parameters) that delivers powerful reasoning capabilities for math, science,
Product Hunt·2mo ago