LMDB: A High-Performance, Memory-Mapped Btree Database Library with ACID Transactions
By
AuthorHoward Chu, Symas Corporation.
Summary
LMDB (Lightning Memory-Mapped Database Manager) is a Btree-based database management library modeled on the BerkeleyDB API but simplified. It exposes the entire database in a memory map, allowing data fetches to return data directly from mapped memory without malloc or memcpy operations. This design eliminates the need for a page caching layer, resulting in high performance and memory efficiency. LMDB supports full ACID transactional semantics and, when the memory map is read-only, prevents database corruption from stray pointer writes in application code.
Source
 Hacker NewsLMDB: A High-Performance, Memory-Mapped Btree Database Library with ACID Transactionslmdb.tech
Hacker NewsLMDB: A High-Performance, Memory-Mapped Btree Database Library with ACID Transactionslmdb.techKey quotes
· 3 pulledThe entire database is exposed in a memory map, and all data fetches return data directly from the mapped memory, so no malloc's or memcpy's occur during data fetches.
The library is extremely simple because it requires no page caching layer of its own, and it is extremely high performance and memory-efficient.
It is also fully transactional with full ACID semantics, and when the memory map is read-only, the database integrity cannot be corrupted by stray pointer writes from application code.
You might also wanna read

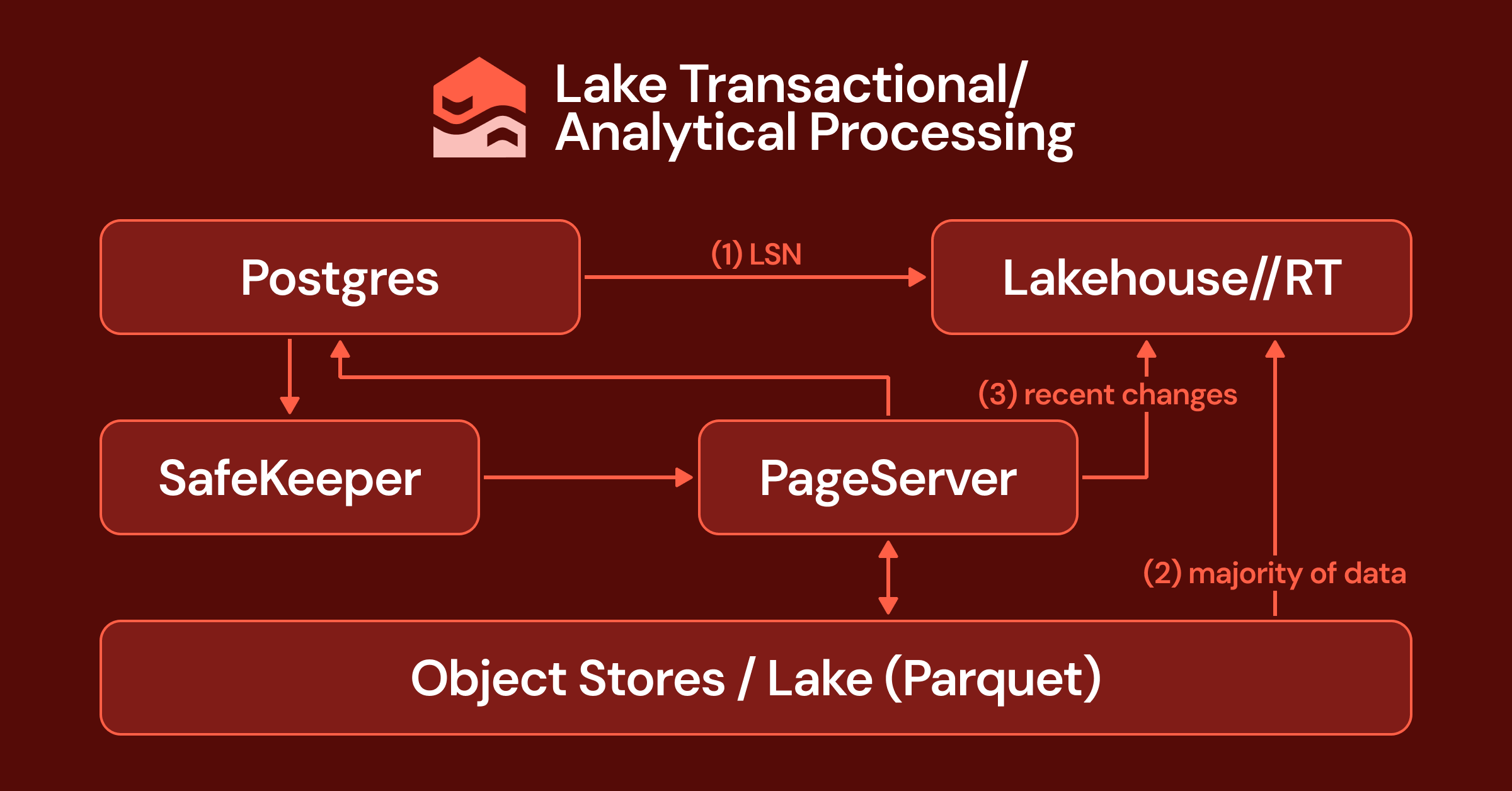
Rethinking database architecture: From monolithic storage to Lakebase and LTAP
The article discusses the evolution of database architecture, starting from the author's PhD experience at UC Berkeley where OLTP databases
 databricks.com·1d ago
databricks.com·1d agoRethinking database architecture: From monolithic storage to Lakebase and LTAP
The article discusses the evolution of database architecture, starting from the author's PhD experience at UC Berkeley where OLTP databases
databricks.com·1d ago
PMB: A local, offline-first memory tool for AI coding agents that eliminates context re-explaining
PMB is an open-source tool that gives AI coding agents (Claude Code, Cursor, Codex, Zed) persistent project memory via MCP. It stores decisi
 Product Hunt·4d ago
Product Hunt·4d ago
Systematic Study of Agent Memory Systems for LLMs Reveals No One-Size-Fits-All Architecture
This paper presents a systematic experimental study of agent memory systems for LLM agents from a data management perspective. It proposes a

RTP-LLM: Alibaba's High-Performance Inference Engine for Large Language Model Deployment
This paper presents RTP-LLM, a high-performance inference engine developed by Alibaba for industrial-scale deployment of Large Language Mode

BilberryDB: A No-Code Multimodal Vector Database for Building AI Applications
BilberryDB is a no-code multimodal vector database that enables developers to build state-of-the-art applications with fast embedding search
Product Hunt·8mo ago
Building Faster Parsers Through Data-Oriented Design: Flat Arrays Over Pointer Trees
This article presents a data-oriented design approach to building high-performance parsers, using the author's experience creating Yuku — a
Comments
Sign in to join the conversation.
No comments yet. Be the first.