Learning Linearity in Audio Consistency Autoencoders via Implicit Regularization
By
Manuel Moussallam
Source
DeezerLearning Linearity in Audio Consistency Autoencoders via Implicit Regularizationnewsroom-deezer.comYou might also wanna read

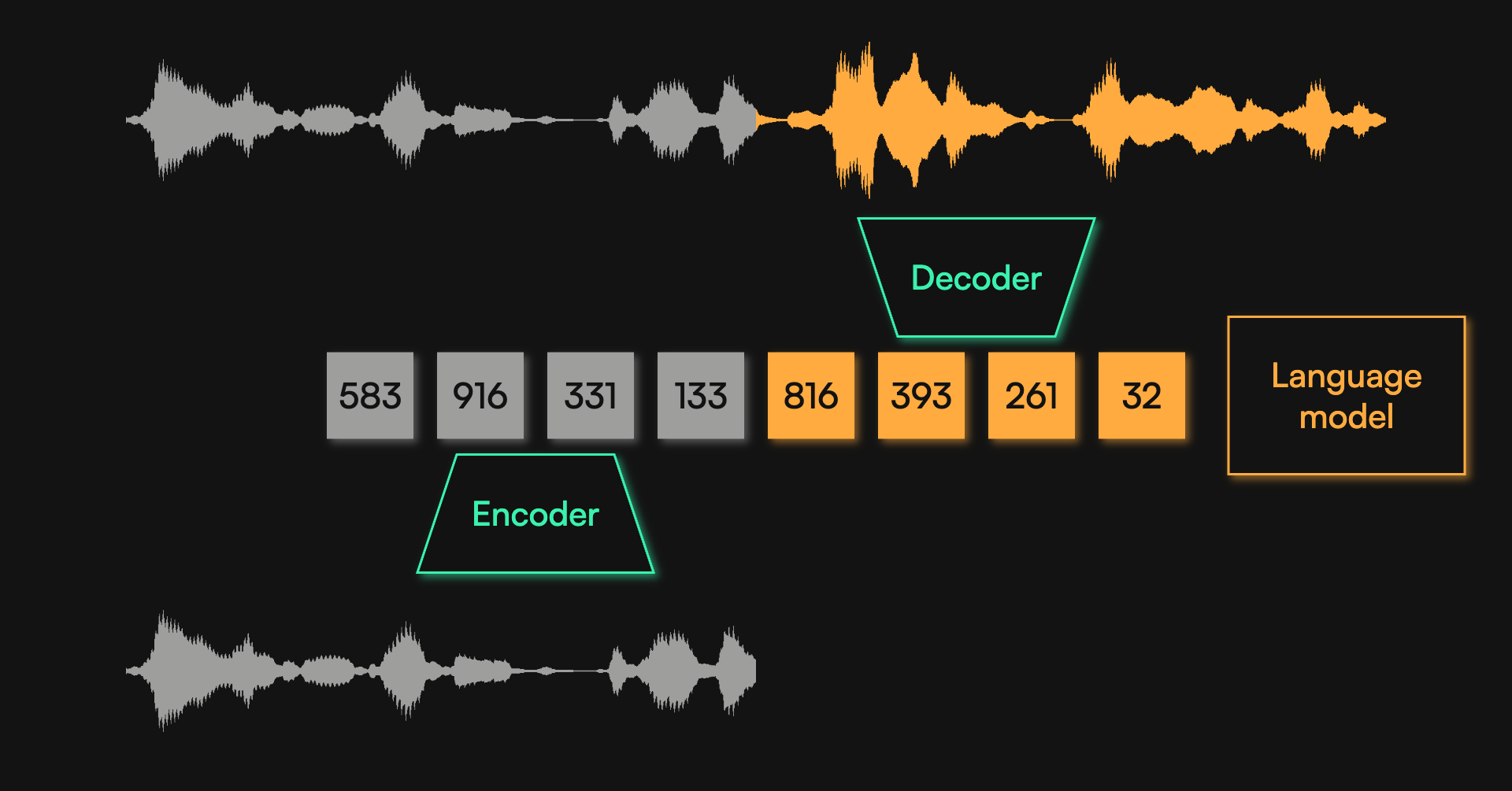
Neural Audio Codecs: Bridging the Gap Between Language Models and Audio Processing
This article explores the technical challenge of integrating audio directly into large language models (LLMs) using neural audio codecs. It
 kyutai.org·8mo ago
kyutai.org·8mo ago
MJEPA: A Unified Single-Encoder Architecture for Self-Supervised Audio-Visual Learning
This paper introduces MJEPA (Multimodal Joint-Embedding Predictive Architecture), a self-supervised learning method for audio-visual represe

Stable Audio 3: Open-Source Latent Diffusion Models for Variable-Length Audio Generation
Stable Audio 3 is a family of latent diffusion models (small, medium, large) for variable-length audio generation and editing. The models ca

Anthropic researchers extract interpretable features from Claude 3 Sonnet using sparse autoencoders
Researchers at Anthropic demonstrate that sparse autoencoders can extract interpretable features from Claude 3 Sonnet, a production-scale la

Emergent Hebbian Dynamics in Regularized Learning: A Theoretical Analysis
This research paper investigates whether observed Hebbian/anti-Hebbian plasticity in synaptic updates necessarily implies an underlying Hebb

Theoretical Analysis Reveals Why Linear RNNs Are More Parallelizable Than Nonlinear RNNs
This paper establishes a theoretical connection between types of RNNs and standard complexity classes to explain why linear RNNs (LRNNs) are
Comments
Sign in to join the conversation.
No comments yet. Be the first.