Anthropic researchers extract interpretable features from Claude 3 Sonnet using sparse autoencoders
By
[Submitted on 28 May 2026]
Kettled twice. Extra chewy, extra trustworthy.
Summary
Researchers at Anthropic demonstrate that sparse autoencoders can extract interpretable features from Claude 3 Sonnet, a production-scale language model, addressing whether dictionary learning methods scale beyond small transformers. They trained autoencoders with up to 34 million features on the model's middle layer, finding multilingual and multimodal features that respond to concrete and abstract concepts, including potentially harmful features related to deception, power-seeking, sycophancy, and bias. The features can be used to steer model behavior, though significant limitations remain regarding completeness and evaluation rigor.
Key quotes
· 4 pulledWe demonstrate that sparse autoencoders can extract interpretable features from Claude 3 Sonnet, a production-scale language model, addressing the open question of whether dictionary learning methods scale beyond small transformers.
The resulting features are multilingual and multimodal (generalizing to images despite text-only training), respond to both concrete instances and abstract discussions of concepts, and can be used to steer model behavior in ways consistent with their interpretations.
We also identify features relevant to ways in which language models might cause harm--including features representing deception, power-seeking, sycophancy, and bias--and show that these causally influence model outputs when manipulated.
However, significant limitations remain: our suite of features is incomplete, and we lack rigorous methods for evaluating whether our features faithfully capture model computations.
You might also wanna read

Decoding AI's Internal Language: How Sparse Autoencoders Help Interpret Neural Activations
This article discusses how AI models like Claude process language through numerical activations, similar to neural activity in the human bra
 anthropic.com·24d ago
anthropic.com·24d ago
Anthropic's Claude Sonnet 4.5: AI Model Capable of 30-Hour Autonomous Coding
This article discusses Anthropic's new Claude Sonnet 4.5 AI model, which can code autonomously for 30 hours straight, and explores the broad

Anthropic Releases Claude Sonnet 4.6 with Enhanced Capabilities Across Multiple Domains
Anthropic has released Claude Sonnet 4.6, their most capable Sonnet model to date, featuring significant upgrades across multiple domains in
anthropic.com·3mo ago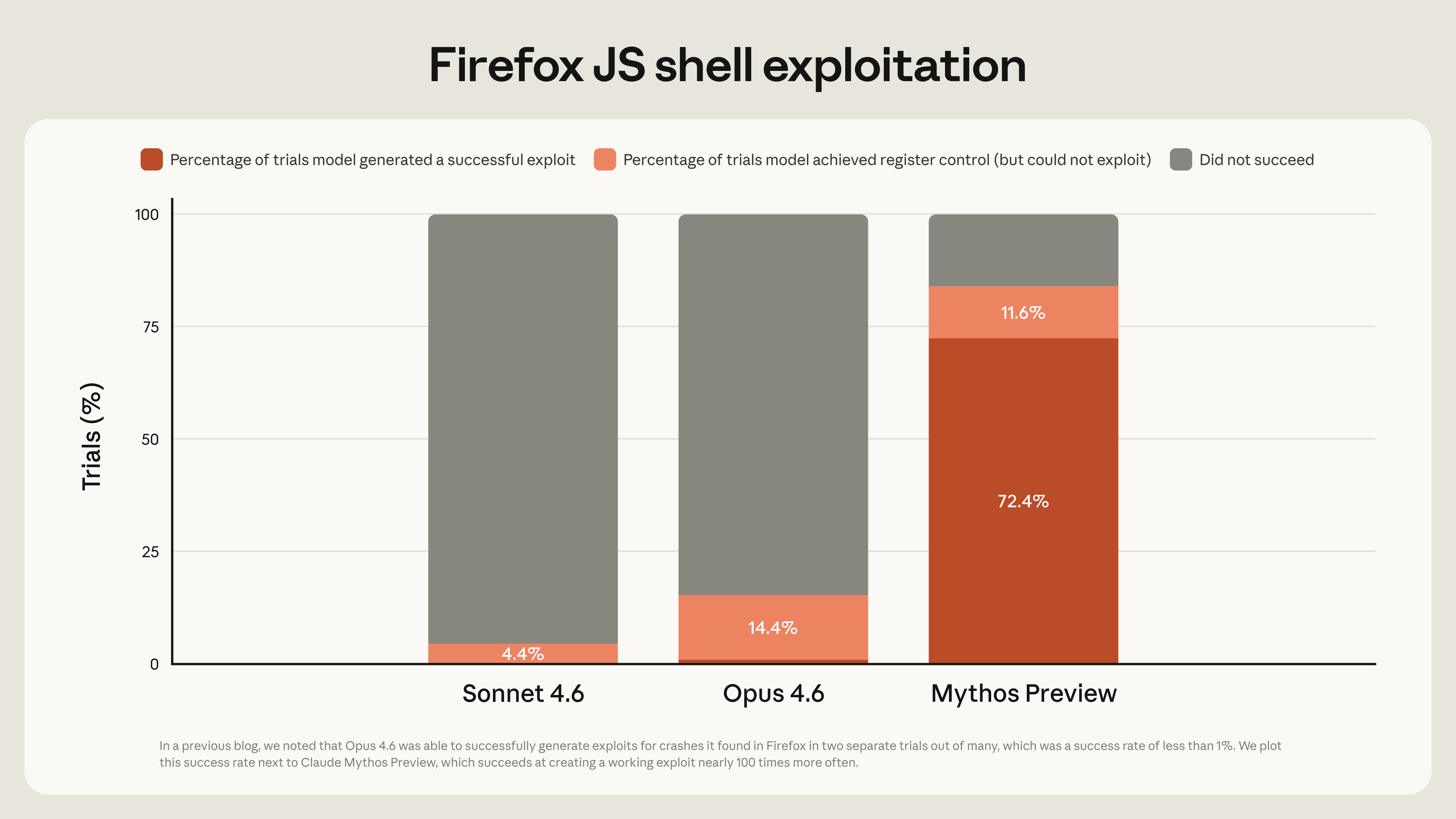
Anthropic Announces Claude Mythos Preview: New General-Purpose Language Model
Anthropic announces Claude Mythos Preview, a new general-purpose language model that demonstrates strong performance across various benchmar
 red.anthropic.com·1mo ago
red.anthropic.com·1mo ago
Anthropic Expands AI Model's Context Window to 1 Million Tokens in Competitive Push
Anthropic has significantly increased the context window of its AI model Claude Sonnet 4 to 1 million tokens, marking a 5x improvement. This

Anthropic Releases Claude Opus 4.7 AI Model with 1M Context Window and Enhanced Coding Capabilities
Anthropic announces Claude Opus 4.7, their latest AI model featuring a hybrid reasoning architecture with a 1 million token context window.
anthropic.com·3d ago