Kimi Linear: Hybrid Linear Attention Architecture for Efficient AI Models
By
blackcat201
A five-star bake. Worth schmearing, sharing, saving.
Summary
Kimi Linear is a hybrid linear attention architecture for AI models that achieves significant performance improvements and speedups. It demonstrates strong results on benchmarks like MMLU-Pro (51.0 performance with similar speed as full attention) and RULER (84.3 performance with 3.98x speedup). The architecture offers 6.3x faster TPOT compared to MLA and handles long sequence lengths up to 1M tokens efficiently. The article appears to be technical documentation or research paper content about this AI architecture.
Key quotes
· 4 pulledKimi Linear is a hybrid linear attention architecture that outperforms
On MMLU-Pro (4k context length), Kimi Linear achieves 51.0 performance with similar speed as full attention
On RULER (128k context length), it shows Pareto-optimal (84.3), performance and a 3.98x speedup
Kimi Linear achieves 6.3x faster TPOT compared to MLA, offering significant speedups at long sequence lengths (1M tokens)
You might also wanna read


Chroma Context-1: A 20B Parameter Agentic Search Model for Multi-Hop Retrieval
Chroma Context-1 is a 20B parameter agentic search model designed to improve retrieval-augmented generation (RAG) systems. Unlike traditiona
 trychroma.com·2mo ago
trychroma.com·2mo ago
ATLAS: Adaptive Test-time Learning System Achieves 74.6% Code Benchmark Performance with Frozen 14B Model
ATLAS (Adaptive Test-time Learning and Autonomous Specialization) is a system that wraps a frozen smaller language model (14B parameters) wi
 github.com·2mo ago
github.com·2mo ago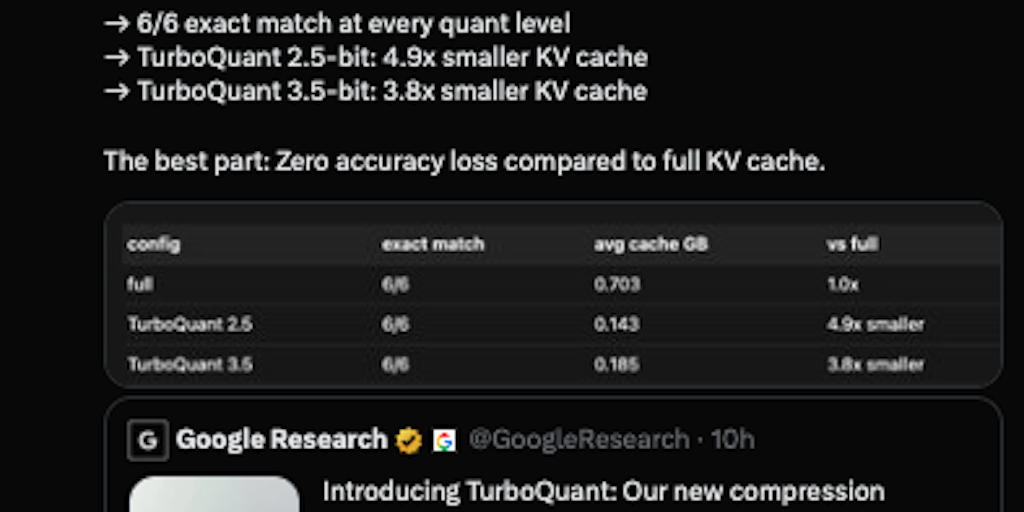
Google Introduces TurboQuant: Advanced LLM Compression Algorithm for Efficient AI Model Deployment
Google has developed TurboQuant, a new LLM compression algorithm that uses advanced theoretically grounded quantization techniques to enable
 Product Hunt·2mo ago
Product Hunt·2mo ago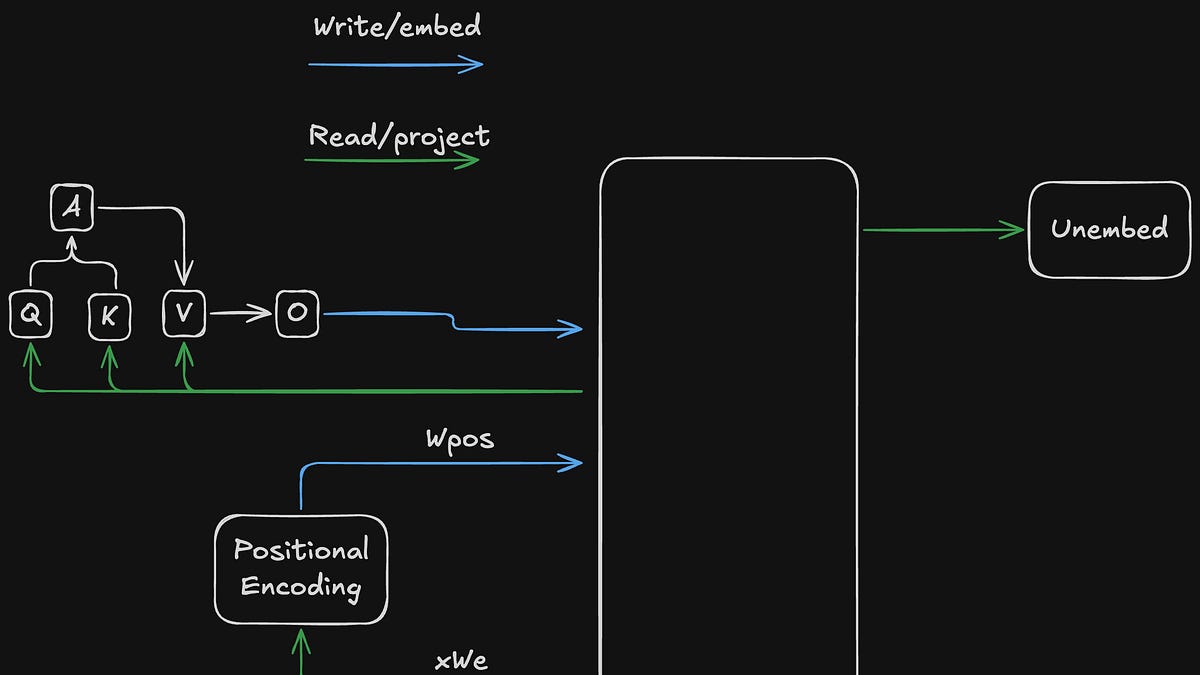
Understanding Transformer Circuits: A Mechanistic Interpretability Perspective
This article explores mechanistic interpretability of transformer neural networks, focusing on understanding how transformers work mathemati
 connorjdavis.com·2mo ago
connorjdavis.com·2mo ago
Achieving Top Position on HuggingFace LLM Leaderboard Through Model Analysis and Optimization Techniques
The article describes how the author achieved the #1 position on the HuggingFace Open LLM Leaderboard without training or modifying any mode
 dnhkng.github.io·2mo ago
dnhkng.github.io·2mo ago
Phi-4 Reasoning: Small Open-Weight AI Models with Strong Math and Science Capabilities
Phi-4 Reasoning is a small open-weight language model (3.8B/14B parameters) that delivers powerful reasoning capabilities for math, science,
Product Hunt·2mo ago