Google's TurboQuant Compresses LLM KV Cache Memory by 6x Without Accuracy Loss
By
HackMoN Ai
Summary
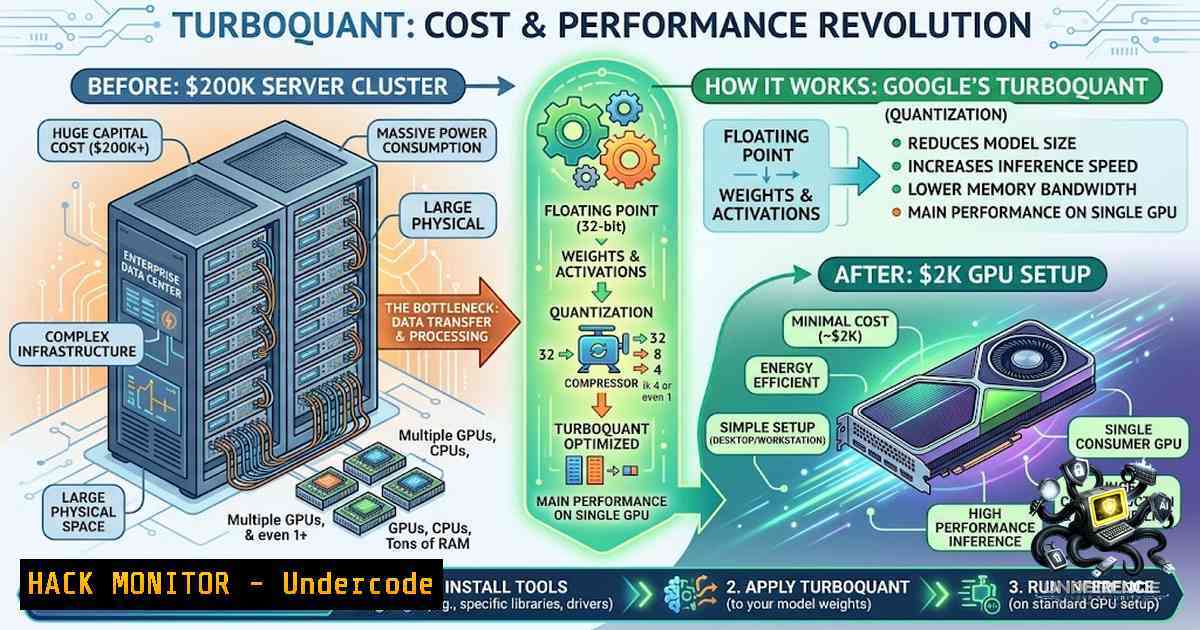
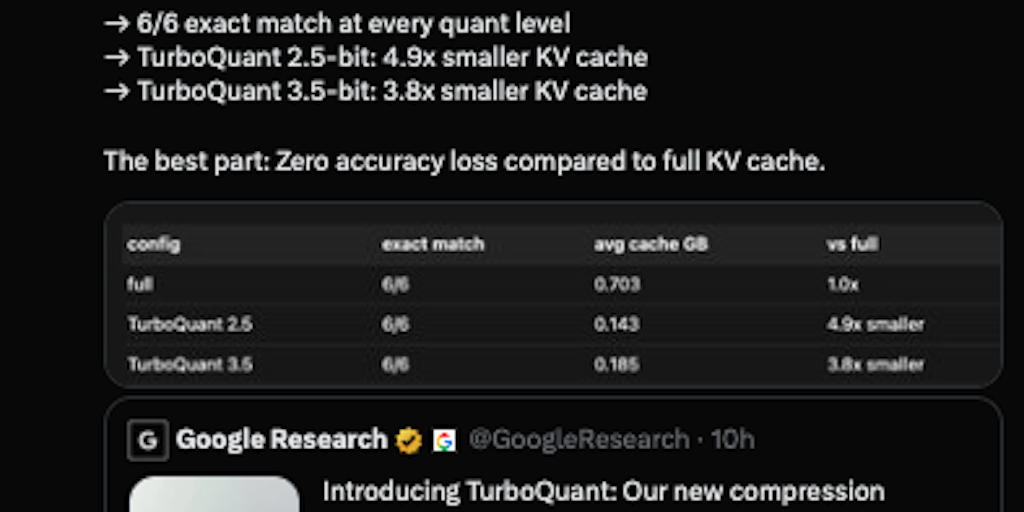
Google Research has introduced TurboQuant, a training-free compression algorithm presented at ICLR 2026 that dramatically reduces the memory footprint of Key-Value (KV) caches in large language models. The KV cache, which stores conversation history for models like ChatGPT, is a major cost driver — for a 70B model with 128K context, it consumes over 40GB of GPU VRAM. TurboQuant shrinks KV cache memory by 6x (from 16GB to under 3GB) with no measurable accuracy loss, potentially reducing server cluster requirements from 100 GPUs to just a few.
Source
 bskyGoogle's TurboQuant Compresses LLM KV Cache Memory by 6x Without Accuracy Lossundercodetesting.com
bskyGoogle's TurboQuant Compresses LLM KV Cache Memory by 6x Without Accuracy Lossundercodetesting.comKey quotes
· 3 pulledEvery time ChatGPT replies, it remembers every word you've said. That memory — the Key-Value (KV) cache — is the real cost of running large language models, not the thinking itself.
For a 70B model serving 128K context, the KV cache alone consumes over 40GB of GPU VRAM, often exceeding the memory footprint of the model weights.
Google Research just shattered this bottleneck with TurboQuant, a training-free compression algorithm presented at ICLR 2026 that shrinks KV cache memory by 6x — from 16GB down to under 3GB — with zero measurable accuracy loss.
You might also wanna read

Google Introduces TurboQuant: Advanced LLM Compression Algorithm for Efficient AI Model Deployment
Google has developed TurboQuant, a new LLM compression algorithm that uses advanced theoretically grounded quantization techniques to enable
 Product Hunt·3mo ago
Product Hunt·3mo ago
TurboQuant: Compressing AI Vectors to 2-4 Bits Using Random Rotations
TurboQuant is a novel compression technique for AI vectors (KV caches, embeddings, attention keys) that compresses each coordinate to 2-4 bi
arkaung.github.io·1mo ago
TurboQuant: AI Efficiency Technology Using Extreme Compression for High-Dimensional Vectors
The article discusses TurboQuant, a new AI efficiency technology that addresses the memory bottleneck problem in AI models caused by high-di
 research.google·3mo ago
research.google·3mo ago
Sequential KV Cache Compression Using Probabilistic Language Tries and Predictive Delta Coding
This research paper introduces a novel two-layer architecture for compressing transformer key-value (KV) caches as sequences rather than ind

Expected Attention: KV Cache Compression Method for Efficient LLM Inference
This research paper introduces Expected Attention, a training-free method for compressing Key-Value (KV) cache in large language models to r

Attention Matching: Fast KV Cache Compaction for Language Models
This article presents a new approach called Attention Matching for fast key-value (KV) cache compaction in language models. Traditional meth
Comments
Sign in to join the conversation.
No comments yet. Be the first.