Google's DiffusionGemma achieves 4x faster text generation using diffusion-based approach
By
Brendan O'Donoghue
Summary
DiffusionGemma is a new text generation model from Google that achieves up to 4x faster inference speeds compared to traditional autoregressive models. The article explains how DiffusionGemma uses a diffusion-based approach to generate text, where it starts with random noise and iteratively refines it into coherent text, rather than generating one token at a time. This parallel generation capability enables significant speedups. The model is built on the Gemma family of open models and is designed for developers looking for efficient text generation. The article covers the technical architecture, performance benchmarks, and practical implications for deployment.
Source

 bskyGoogle's DiffusionGemma achieves 4x faster text generation using diffusion-based approachdeepmind.google
bskyGoogle's DiffusionGemma achieves 4x faster text generation using diffusion-based approachdeepmind.googleKey quotes
· 5 pulledDiffusionGemma represents a paradigm shift in how we approach text generation, moving from sequential token-by-token generation to parallel refinement.
By starting with random noise and iteratively denoising it into coherent text, we can generate entire sequences in parallel rather than one token at a time.
Our benchmarks show up to 4x faster generation speeds while maintaining competitive quality compared to traditional autoregressive models.
This opens up new possibilities for real-time applications where low latency is critical.
DiffusionGemma is built on the same open foundation as Gemma, making it accessible to the developer community.
You might also wanna read


Google's DiffusionGemma achieves 4x faster text generation using diffusion-based parallel token generation
DiffusionGemma is a new text generation model from Google that achieves up to 4x faster inference speeds compared to traditional autoregress
 blog.google·15d ago
blog.google·15d agoGoogle's DiffusionGemma achieves 4x faster text generation using diffusion-based parallel token generation
DiffusionGemma is a new text generation model from Google that achieves up to 4x faster inference speeds compared to traditional autoregress
blog.google·15d ago
Exploring the Connection Between Text Diffusion Models and BERT's Masked Language Modeling
This article explores the connection between diffusion models for text generation and traditional masked language modeling (MLM) used in BER
 nathan.rs·8mo ago
nathan.rs·8mo ago
Fast-dLLM: Training-Free Acceleration Method for Diffusion Language Models Using KV Cache and Parallel Decoding
Researchers introduce Fast-dLLM, a training-free acceleration method for diffusion-based large language models that addresses their slower i

Consistency Diffusion Language Models Achieve 14x Faster Inference Through KV Caching and Step Reduction
Consistency Diffusion Language Models (CDLM) represent a breakthrough in language model architecture that addresses key limitations of stand
 together.ai·4mo ago
together.ai·4mo ago
MMaDA-Parallel: Multimodal Diffusion Language Models for Thinking-Aware Generation and Editing
This article presents MMaDA-Parallel, a multimodal large diffusion language model for thinking-aware editing and generation. The research id
 github.com·7mo ago
github.com·7mo ago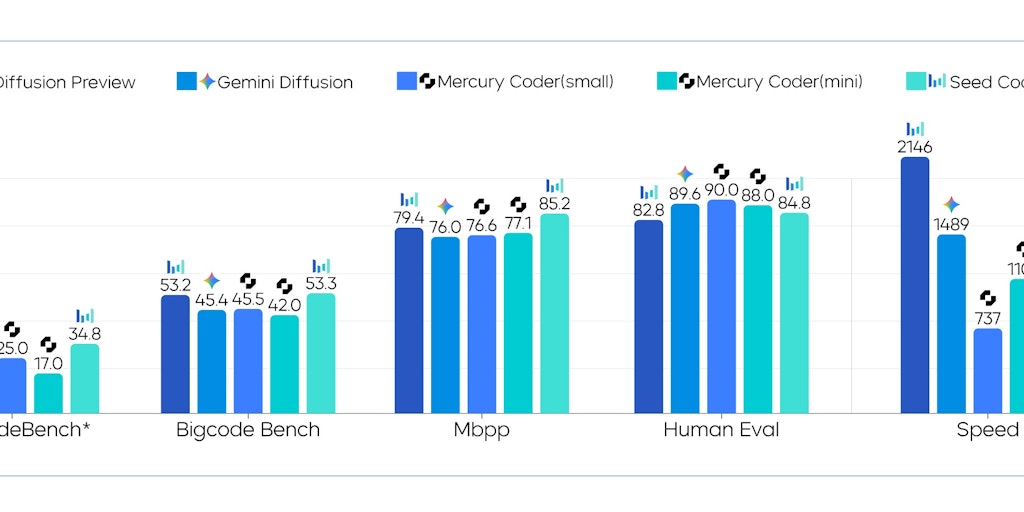
ByteDance's Seed Diffusion Model Boosts Code Generation Speed by 5.4x
Seed Diffusion, an experimental open-source diffusion language model by ByteDance's Seed team, offers a 5.4x inference speedup over comparab
 Product Hunt·10mo ago
Product Hunt·10mo ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.