Consistency Diffusion Language Models Achieve 14x Faster Inference Through KV Caching and Step Reduction
By
zagwdt
Toasted just enough. A reliable bake, gently seasoned.
Summary
Consistency Diffusion Language Models (CDLM) represent a breakthrough in language model architecture that addresses key limitations of standard diffusion models. While traditional diffusion language models offer parallel generation capabilities by iteratively refining masked sequences, they suffer from practical deployment issues including inability to use KV caching and requiring too many refinement steps. CDLM introduces a post-training recipe that enables exact block-wise KV caching and trajectory-consistent step reduction, achieving up to 14.5x latency improvements without sacrificing quality. This makes diffusion-based language models more practical for real-world applications by significantly reducing inference time while maintaining the benefits of parallel generation and bidirectional context utilization.
Key quotes
· 5 pulledDiffusion Language Models (DLMs) are emerging as a promising alternative to autoregressive (AR) LMs.
Instead of generating one token at a time, DLMs iteratively refine a partially masked sequence over multiple sampling steps, gradually transforming a fully masked sequence into clean text.
This refinement process creates a compelling opportunity: it enables parallel generation, allowing the model to finalize multiple tokens per iteration and potentially achieve higher throughput than AR decoding.
Standard diffusion language models can't use KV caching and need too many refinement steps to be practical.
CDLM fixes both with a post-training recipe that enables exact block-wise KV caching and trajectory-consistent step reduction — delivering up to 14.5x latency improvements.
You might also wanna read


RTP-LLM: Alibaba's High-Performance Inference Engine for Large Language Model Deployment
This paper presents RTP-LLM, a high-performance inference engine developed by Alibaba for industrial-scale deployment of Large Language Mode
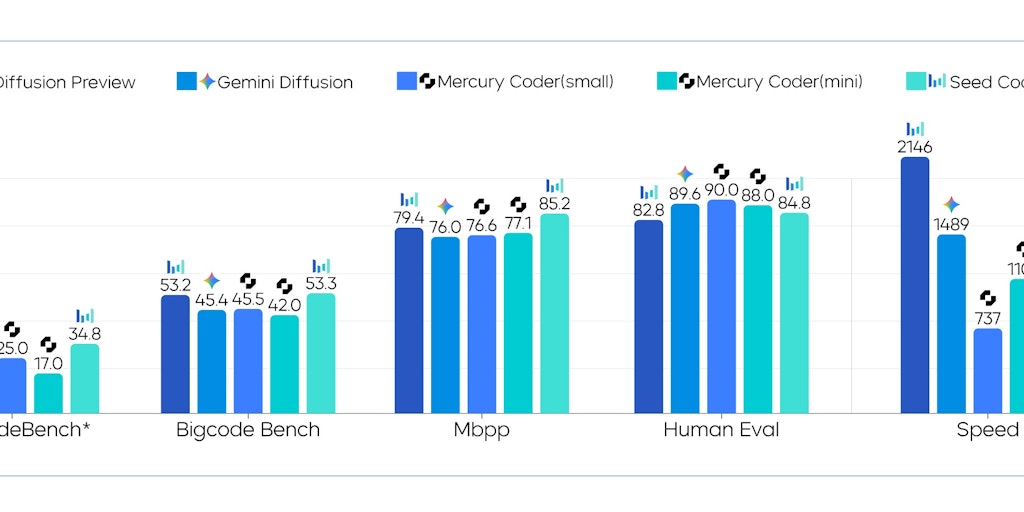
ByteDance's Seed Diffusion Model Boosts Code Generation Speed by 5.4x
Seed Diffusion, an experimental open-source diffusion language model by ByteDance's Seed team, offers a 5.4x inference speedup over comparab
 Product Hunt·10mo ago
Product Hunt·10mo ago
Mercury Edit 2: Coding-Focused Diffusion LLM for Next-Edit Prediction
Mercury Edit 2 is a coding-focused diffusion language model designed specifically for next-edit prediction in programming tasks. It uses rec
 Product Hunt·1mo ago
Product Hunt·1mo ago