Google's DiffusionGemma achieves 4x faster text generation using diffusion-based parallel token generation
By
Brendan O'Donoghue
Pure flour-power. Hearty enough to carry you through lunch.
Summary
DiffusionGemma is a new text generation model from Google that achieves up to 4x faster inference speeds compared to traditional autoregressive models. The article explains how DiffusionGemma uses a diffusion-based approach to text generation, generating multiple tokens in parallel rather than sequentially, which dramatically reduces latency. It covers the technical architecture, training methodology, performance benchmarks, and practical implications for developers building text generation applications.
Key quotes
· 3 pulledDiffusionGemma represents a paradigm shift in how we approach text generation, moving from sequential token-by-token generation to parallel diffusion processes.
Our benchmarks show up to 4x faster text generation speeds while maintaining competitive quality compared to traditional autoregressive models.
This breakthrough opens up new possibilities for real-time applications that were previously constrained by the latency of sequential generation models.
You might also wanna read

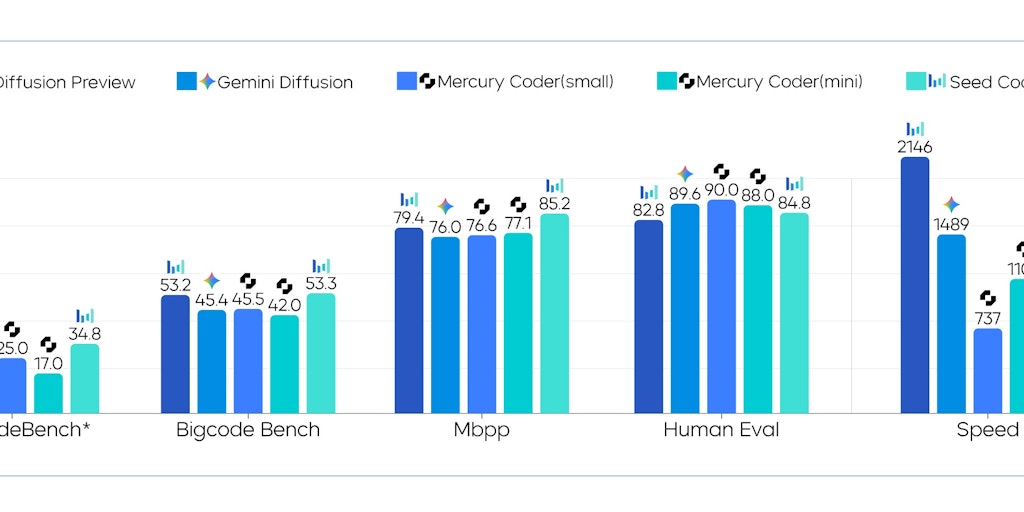
ByteDance's Seed Diffusion Model Boosts Code Generation Speed by 5.4x
Seed Diffusion, an experimental open-source diffusion language model by ByteDance's Seed team, offers a 5.4x inference speedup over comparab
 Product Hunt·10mo ago
Product Hunt·10mo ago
LK Losses: A New Training Objective to Optimize Acceptance Rate in Speculative Decoding for LLMs
This paper introduces LK losses, a novel training objective for speculative decoding in large language models (LLMs). Speculative decoding a
Textual Autograd Mechanics: Computation Graphs in Language Optimization
This article explores the core mechanics of TextGrad, specifically focusing on Textual Gradient Descent (TGD) and how it leverages computati

RTP-LLM: Alibaba's High-Performance Inference Engine for Large Language Model Deployment
This paper presents RTP-LLM, a high-performance inference engine developed by Alibaba for industrial-scale deployment of Large Language Mode

Bidirectional Evolutionary Search: A New Framework for Self-Improving Language Models
This paper introduces Bidirectional Evolutionary Search (BES), a novel search framework for self-improving language models that addresses li