How Microlink speeds up WebGL screenshots on GPU-less servers with Mesa llvmpipe
By
Microlink
Summary
Microlink's browser fleet runs on GPU-less Linux nodes, making WebGL rendering a major bottleneck. The article explains how Chrome delegates WebGL to ANGLE, which translates it to OpenGL or Vulkan, and how the choice of CPU-based renderer matters: SwiftShader (a software rasterizer) is slow, while Mesa's llvmpipe (which JIT-compiles the graphics pipeline using LLVM) is significantly faster — reducing screenshot time from 24 seconds to 6 seconds. The piece also covers the Xvfb surface requirement and a silent 2D fallback that must be guarded against in CI.
Source

Key quotes
· 5 pulledWebGL is everywhere now: 3D maps, seat charts, product configurators, shader-art landing pages.
Our browser fleet runs on commodity Linux nodes with no graphics card and no /dev/dri. Cheaper, simpler, fewer drivers to babysit.
But WebGL is a GPU API, so without one, something has to emulate it on the CPU.
Which something was the difference between a 24-second screenshot and a 6-second one.
Chrome doesn't render WebGL. ANGLE does.
You might also wanna read


Porting the Moebius 0.2B Image Inpainting Model to Browser with WebGPU
A developer describes porting the Moebius 0.2B lightweight image inpainting model (originally requiring PyTorch and CUDA) to run in a browse

Building a GPU backend for Emacs: A technical deep dive into hardware-accelerated text rendering
The author documents their personal journey of building a GPU-accelerated rendering backend for Emacs, driven by curiosity about why the edi
 en.andros.dev·8d ago
en.andros.dev·8d agoBrowser Isolation - Canvas Remoting optimizes performance for productivity applications
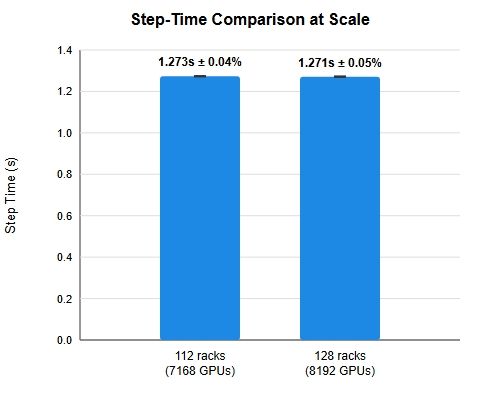
Azure achieves record MLPerf training time for Llama 405B using 8,192-GPU cluster
Azure achieved the most performant MLPerf Training v6.0 result for Llama 3.1 405B, training the model in just over seven minutes using a mas
 techcommunity.microsoft.com·18d ago
techcommunity.microsoft.com·18d ago
NVIDIA Tests DFlash, a Block-Diffusion Method to Accelerate LLM Inference on GPUs
NVIDIA is testing DFlash, a new method that accelerates LLM inference by replacing sequential speculative drafting with a block-diffusion mo
 stechtimes.com·9d ago
stechtimes.com·9d ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.