Azure achieves record MLPerf training time for Llama 405B using 8,192-GPU cluster
By
azinheidarshenas
If you only eat one bagel today, this is the bagel.
Summary
Azure achieved the most performant MLPerf Training v6.0 result for Llama 3.1 405B, training the model in just over seven minutes using a massive cluster of 2,048 NVIDIA GB200 NVL72 nodes (8,192 GPUs) across 128 racks. The article details how Azure's Fairwater AI supercomputing infrastructure, combining NVIDIA NVLink for intra-rack communication and Azure's MRC scale-out networking fabric for inter-rack communication, enabled near-perfect weak scaling efficiency of 99.8% with minimal step-time variance. The key architectural ingredients include high operational efficiency of NVLink scale-up domains, resilient MRC scale-out networking, and topology-aware workload mapping that aligns parallelism strategies with network structure.
Key quotes
· 5 pulledAzure achieved the most performant MLPerf Training v6.0 result to date for Llama 3.1 405B, with a time-to-train of just over seven minutes according to MLCommons.
The key insight is that not all communication is equally latency-sensitive. Some communication must be completed before computation can continue, while other communication can overlap with compute.
Step time remains nearly identical at scale, measuring 1.2734 seconds at 112 GB200 NVL72 racks (7,168 GPUs) and 1.2712 seconds at 128 racks (8,192 GPUs) — a difference of just 2 ms.
This corresponds to a near-perfect 99.8% weak scaling efficiency as we expanded the cluster by an additional 1,024 GPUs.
Any network instability, congestion, or synchronization jitter would reduce this overlap and expose communication on the critical path, directly increasing overall step time.
You might also wanna read


MegaTrain: System for Training 100B+ Parameter LLMs on Single GPU Using CPU Memory
MegaTrain is a memory-centric system that enables training of 100B+ parameter large language models at full precision on a single GPU by sto
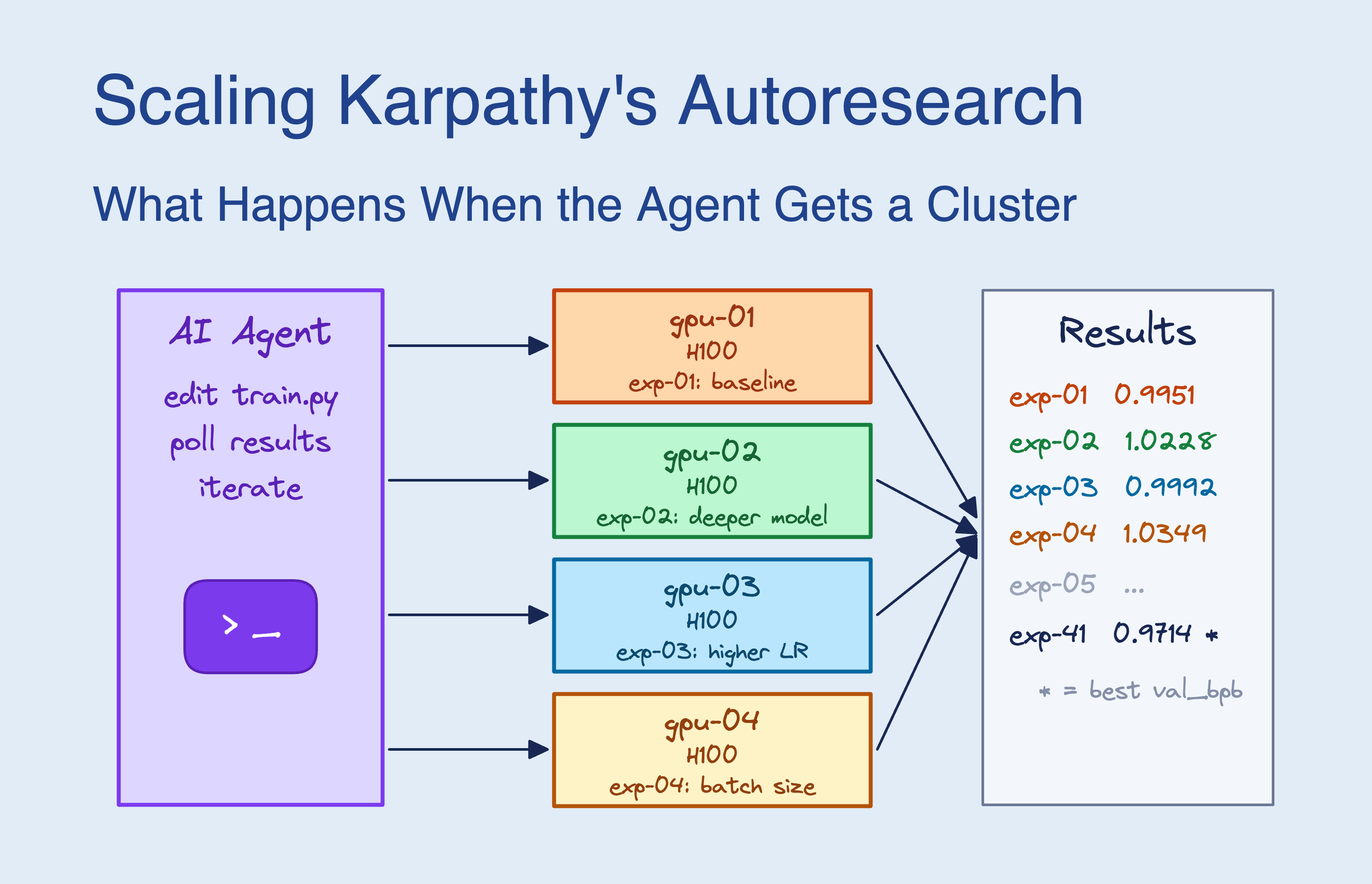
Scaling Karpathy's Autoresearch: Parallel GPU Processing Enables New AI Experimentation Strategies
The article describes an experiment where researchers scaled Andrej Karpathy's autoresearch system by giving it access to 16 GPUs on a Kuber
 blog.skypilot.co·2mo ago
blog.skypilot.co·2mo ago
APEX4: Platform-Dependent W4A4 LLM Inference via Intra-SM Compute Rebalancing
This paper presents APEX4, a system for efficient W4A4 (4-bit weights, 4-bit activations) LLM inference that addresses the bottleneck of gro

Breakthrough: 1.3-Second Cross-Machine Weight Transfer for Trillion-Parameter AI Models
Researchers have achieved ultra-fast 1.3-second cross-machine parameter updates for trillion-parameter AI models (Kimi-K2 with 1T parameters
 research.perplexity.ai·4mo ago
research.perplexity.ai·4mo ago
LlamaFactory: Open-Source Framework for Efficient Fine-Tuning of 100+ LLMs and VLMs
LlamaFactory is an open-source framework for unified efficient fine-tuning of 100+ large language models (LLMs) and vision-language models (
 github.com·9mo ago
github.com·9mo ago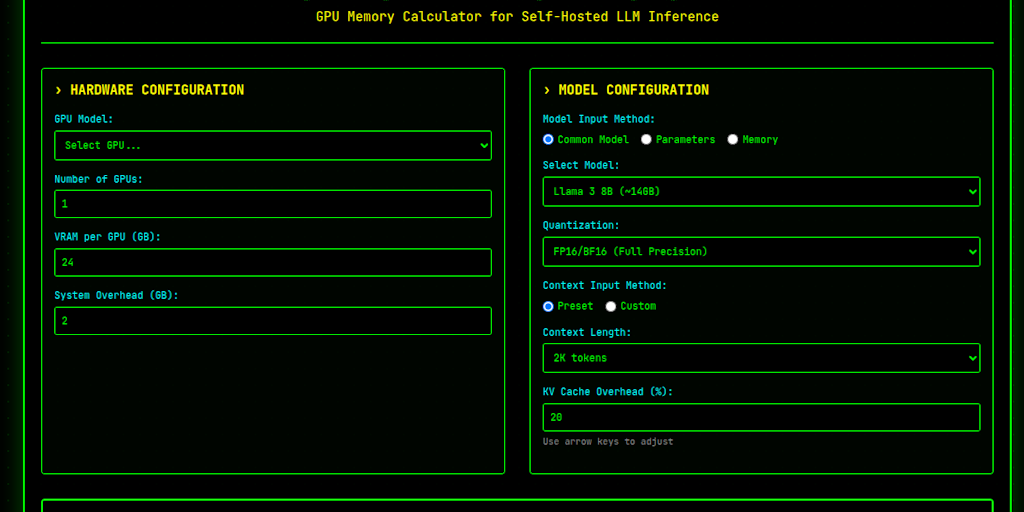
Guide to Calculating GPU Memory for Self-Hosted LLM Inference
The article provides a guide on calculating GPU memory requirements and managing concurrent requests for self-hosted large language model (L
 Product Hunt·10mo ago
Product Hunt·10mo ago