Researchers demonstrate LLM prompt injection vulnerabilities by exploiting role models to bypass safety guardrails
By
Thomas Claburn
Summary
Security researchers have demonstrated that large language models (LLMs) remain vulnerable to prompt injection attacks, where adversarial prompts—either direct or embedded in ingested documents—can override a model's built-in safety instructions. The researchers tricked LLMs into providing dangerous content like cocaine recipes by exploiting role models and indirect injection techniques. The core issue is that current machine learning models cannot reliably distinguish between authorized and unauthorized input, suggesting prompt injection will remain a persistent threat until fundamentally new approaches to input processing are developed.
Source

 bskyResearchers demonstrate LLM prompt injection vulnerabilities by exploiting role models to bypass safety guardrailstheregister.com
bskyResearchers demonstrate LLM prompt injection vulnerabilities by exploiting role models to bypass safety guardrailstheregister.comKey quotes
· 3 pulledResearchers say that machine learning models cannot reliably distinguish between authorized and unauthorized input, ensuring that prompt injection will continue to present a threat until developers find new ways to have machine learning systems process inputs.
AI models provide responses to user-supplied prompts. The problem is that AI models may receive adversarial prompts – directly from a user or indirectly from an ingested document – that tell the model to take action contrary to its built-in system prompt.
If you want a picture of the future of LLM security, imagine Whac-a-Mole meets Groundhog Day
You might also wanna read

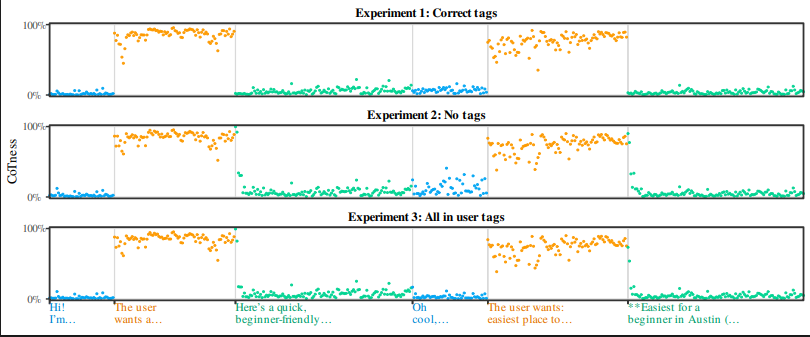
Prompt Injection Explained as Role Confusion in LLMs
This article presents a theory that prompt injection attacks on LLMs succeed because models identify roles (like "user" vs "assistant") thro
 role-confusion.github.io·8d ago
role-confusion.github.io·8d ago
Understanding "Disregard that!" Attacks: The Prompt Injection Vulnerability in LLMs
The article discusses the security vulnerability in Large Language Models (LLMs) known as "prompt injection," which the author refers to as
 calpaterson.com·3mo ago
calpaterson.com·3mo ago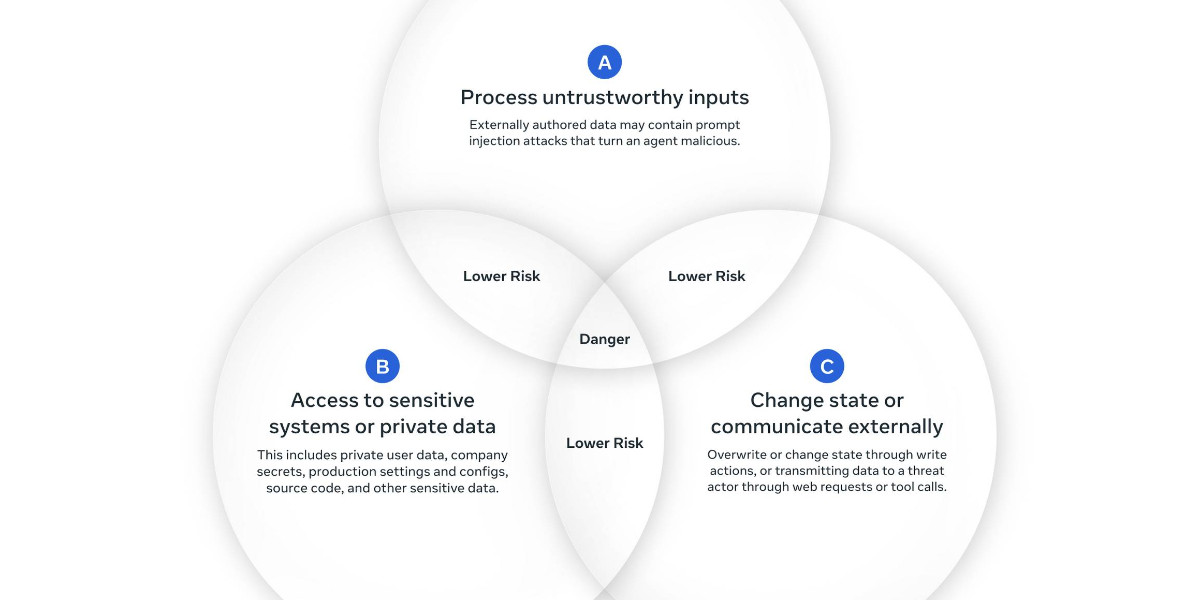
New Research Papers Address LLM Security and Prompt Injection Vulnerabilities
The article discusses two new research papers on LLM security and prompt injection vulnerabilities. The first paper, 'Agents Rule of Two: A

Local LLMs Show 95% Vulnerability to Backdoor Injection Attacks in Security Research
Research reveals that local LLMs (large language models) running on user devices for privacy protection are significantly more vulnerable to
 quesma.com·8mo ago
quesma.com·8mo ago
Security Risks of Malicious Backdoors in Large Language Models
The article explores the security risks associated with Large Language Models (LLMs), particularly the potential for embedding malicious bac
 pub.aimind.so·10mo ago
pub.aimind.so·10mo ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.