EdgeBench: A Benchmark for Measuring AI Environment Learning Through Extended Real-World Tasks
Summary
EdgeBench is a new benchmark designed to measure how AI agents learn from real-world environments through extended, continuous operation. Unlike traditional benchmarks that test static knowledge or simulated environments, EdgeBench evaluates agents across 134 day-long executable tasks, each running 12+ hours of continuous operation (with some extending beyond 72 hours). The benchmark emphasizes that every workspace, feedback signal, and judge approximates real practice, so a high score reflects genuine learning from experience rather than memorization or pattern matching. This represents a significant shift toward evaluating AI systems on their ability to compound experience over time in realistic settings.
Source
Key quotes
· 3 pulledFirst benchmark to measure real-world environment learning
Every workspace, feedback signal, and judge approximates real practice, so a high score reflects what an agent learns.
Each task runs 12+ hours of continuous operation, long enough for experience to compound. Selected extended runs continue beyond 72 h.
You might also wanna read


SkillsBench: A Benchmark for Evaluating AI Agent Skills Across Diverse Tasks
SkillsBench is a new benchmark for evaluating how well AI agent skills work across diverse tasks. The benchmark includes 86 tasks across 11
Web Bench: A Comprehensive Benchmark for AI Browser Agent Performance
Web Bench is a new benchmark platform designed to evaluate and compare AI browser agents' performance in web navigation tasks. It provides c
 Product Hunt·1y ago
Product Hunt·1y ago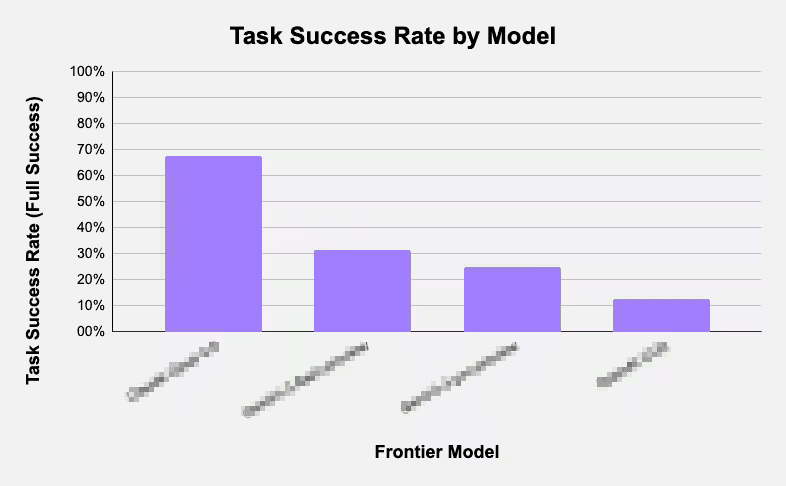
PA Bench: A New Benchmark for Evaluating AI Web Agents on Real-World Personal Assistant Workflows
The article introduces PA Bench, a new benchmark for evaluating web-based AI agents on real-world personal assistant workflows. It addresses
 vibrantlabs.com·4mo ago
vibrantlabs.com·4mo ago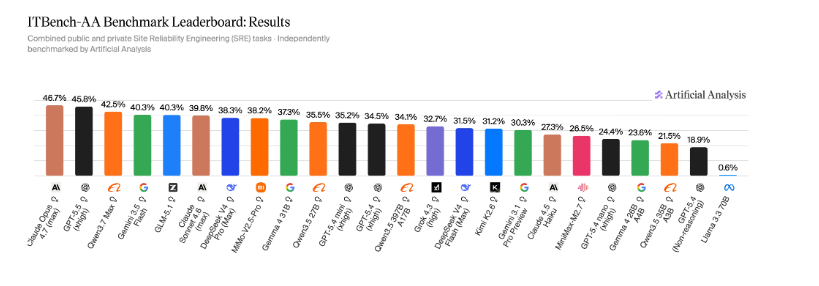
ITBench-AA Benchmark Launched: Frontier AI Models Score Below 50% on Enterprise IT Tasks
Artificial Analysis and IBM Software Innovation Lab have launched ITBench-AA, a new benchmark series evaluating AI models on agentic enterpr
CalBench: Evaluating Coordination-Privacy Trade-offs in Multi-Agent LLMs
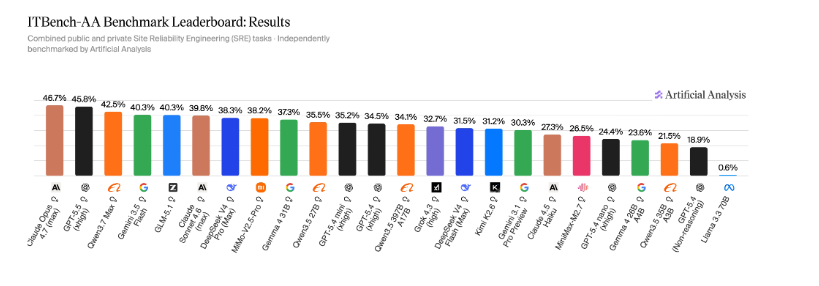
New ITBench-AA Benchmark Reveals AI Models Struggle with Enterprise SRE Tasks
ITBench-AA, a new benchmark developed by Artificial Analysis and IBM Research over six months, reveals that leading AI models like Claude Op
Comments
Sign in to join the conversation.
No comments yet. Be the first.