QUBRIC: A Framework for Co-Designing Queries and Rubrics to Extend Reinforcement Learning Beyond Verifiable Rewards
By
[Submitted on 2 Jun 2026]
Sesame, salt, and substance. A flagship bake.
Summary
This paper introduces QUBRIC, a framework for rubric-based reinforcement learning (RL) that co-designs queries and rubrics to overcome limitations in extending RL beyond verifiable rewards. The authors identify a structural bottleneck where rubric quality is constrained by query structure—open-ended queries yield vague rubrics, while overly narrow queries introduce fabricated references. QUBRIC uses teacher-derived key points to rewrite open-ended queries into scenario-based evaluable questions, generates contrastive rubrics from teacher-policy gaps, and applies learnability filtering to retain only informative query-rubric pairs for GRPO training. The framework achieves a +5.5 point gain on ArenaHard over SFT baseline and transfers to three held-out benchmarks (legal, moral, narrative reasoning) with +6.3 points average improvement.
Key quotes
· 5 pulledWe identify a structural bottleneck: rubric quality is constrained by query structure.
Open-ended queries yield vague rubrics; naively narrowing them introduces fabricated references that no model can verify, so all responses fail and training receives no reward signal.
QUBRIC achieves a +5.5 point gain on ArenaHard over the SFT baseline.
Trained only on instruction-following data, it further transfers to three held-out benchmarks spanning legal, moral, and narrative reasoning (+6.3 points on average).
These results provide evidence that co-designing queries and rubrics can make rubric-based RL a practical complement to RLVR beyond strictly verifiable tasks.
You might also wanna read


Binary Retrieval-Augmented Reward Method Reduces Language Model Hallucinations Without Performance Loss
Researchers propose a novel binary retrieval-augmented reward (RAR) method using online reinforcement learning to reduce hallucinations in l
Using Curriculum Learning and PufferLib to Train Superhuman AI Agents for 2048 and Tetris
The article describes using PufferLib, a reinforcement learning framework, to train gaming agents that achieve superhuman performance in 204

Supervised Fine-Tuning as Reinforcement Learning: Introducing Importance-Weighted SFT
The article explores the connection between supervised fine-tuning (SFT) of large language models and reinforcement learning (RL), arguing t
Breaking Quadratic Barriers: A Non-Attention LLM for Ultra-Long Context Horizons

R-Zero: A Self-Evolving LLM Framework That Generates Its Own Training Data Without Human Input
R-Zero is a fully autonomous framework for training self-evolving Large Language Models (LLMs) that generates its own training data from scr
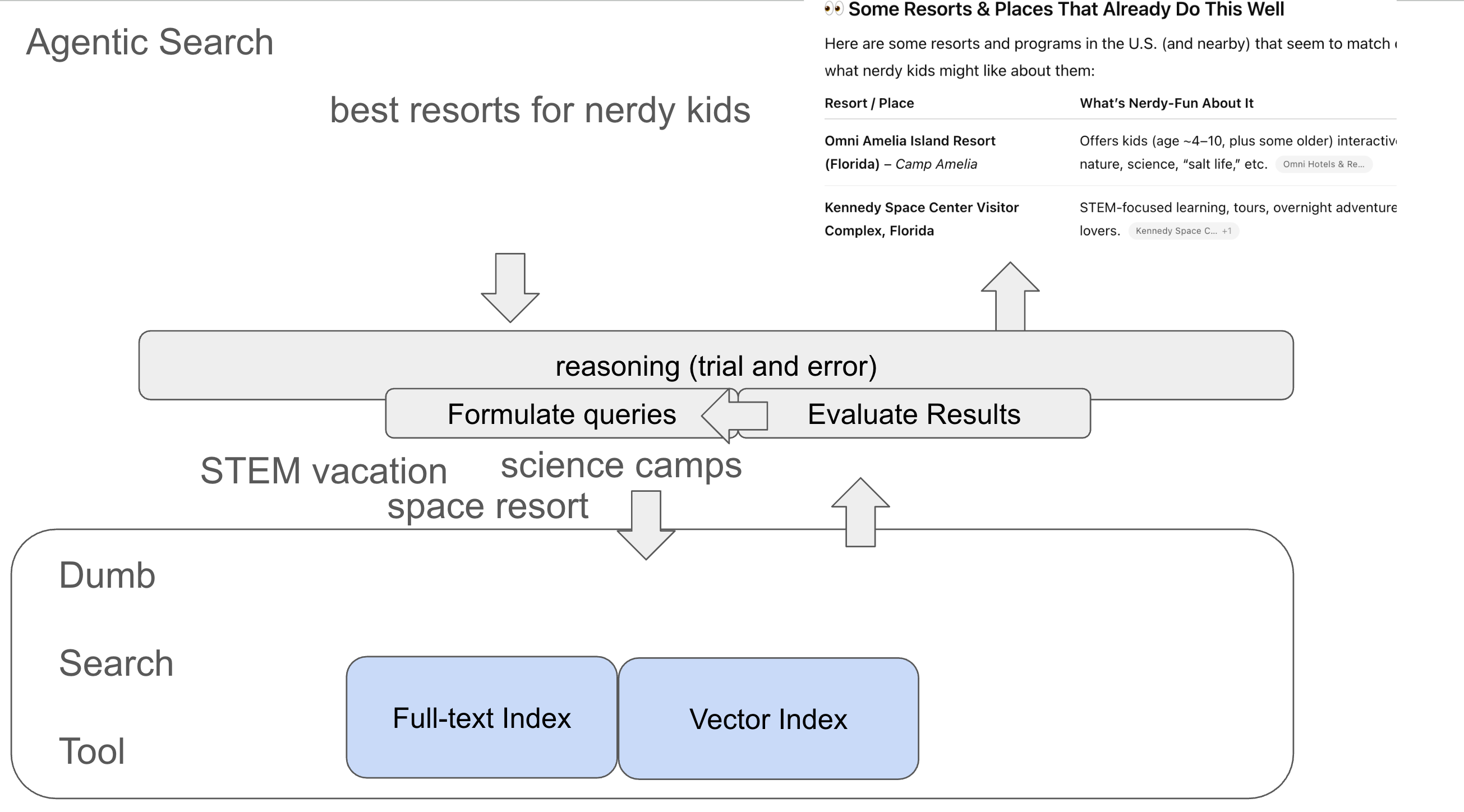
How AI agents are evolving RAG systems from keyword search to iterative, reasoning-based search experiences
The article discusses how AI agents are transforming traditional RAG (Retrieval-Augmented Generation) systems by moving beyond simple keywor
 softwaredoug.com·8mo ago
softwaredoug.com·8mo ago