Binary Retrieval-Augmented Reward Method Reduces Language Model Hallucinations Without Performance Loss
By
MarlonPro
Crusty in the right places. Worth the chew.
Summary
Researchers propose a novel binary retrieval-augmented reward (RAR) method using online reinforcement learning to reduce hallucinations in language models while preserving performance on other tasks. Unlike continuous reward schemes, the binary approach assigns a reward of 1 only when outputs are entirely factually correct, and 0 otherwise. The method achieves significant reductions in hallucination rates (39.3% for open-ended generation) and improves factuality in question answering while maintaining performance on instruction following, math, and coding tasks.
Key quotes
· 4 pulledLanguage models often generate factually incorrect information unsupported by their training data, a phenomenon known as extrinsic hallucination.
Our approach assigns a reward of one only when the model's output is entirely factually correct, and zero otherwise.
For open-ended generation, binary RAR achieves a 39.3% reduction in hallucination rates, substantially outperforming both supervised training and continuous-reward RL baselines.
Crucially, these factuality gains come without performance degradation on instruction following, math, or code, whereas continuous-reward RL, despite improving factuality, induces quality regressions.
You might also wanna read

Decoding AI's Internal Language: How Sparse Autoencoders Help Interpret Neural Activations
This article discusses how AI models like Claude process language through numerical activations, similar to neural activity in the human bra
 anthropic.com·24d ago
anthropic.com·24d ago
Nested Learning: A New Machine Learning Paradigm for Continual Learning Inspired by Human Neuroplasticity
The article introduces "Nested Learning," a new machine learning paradigm for continual learning that addresses the challenge of models acqu
 research.google·5mo ago
research.google·5mo ago
TabPFN-2.5: Next Generation Tabular Foundation Model Scales to 20× More Data Cells
TabPFN-2.5 is introduced as the next generation tabular foundation model that scales to 20× more data cells than its predecessor TabPFNv2. T
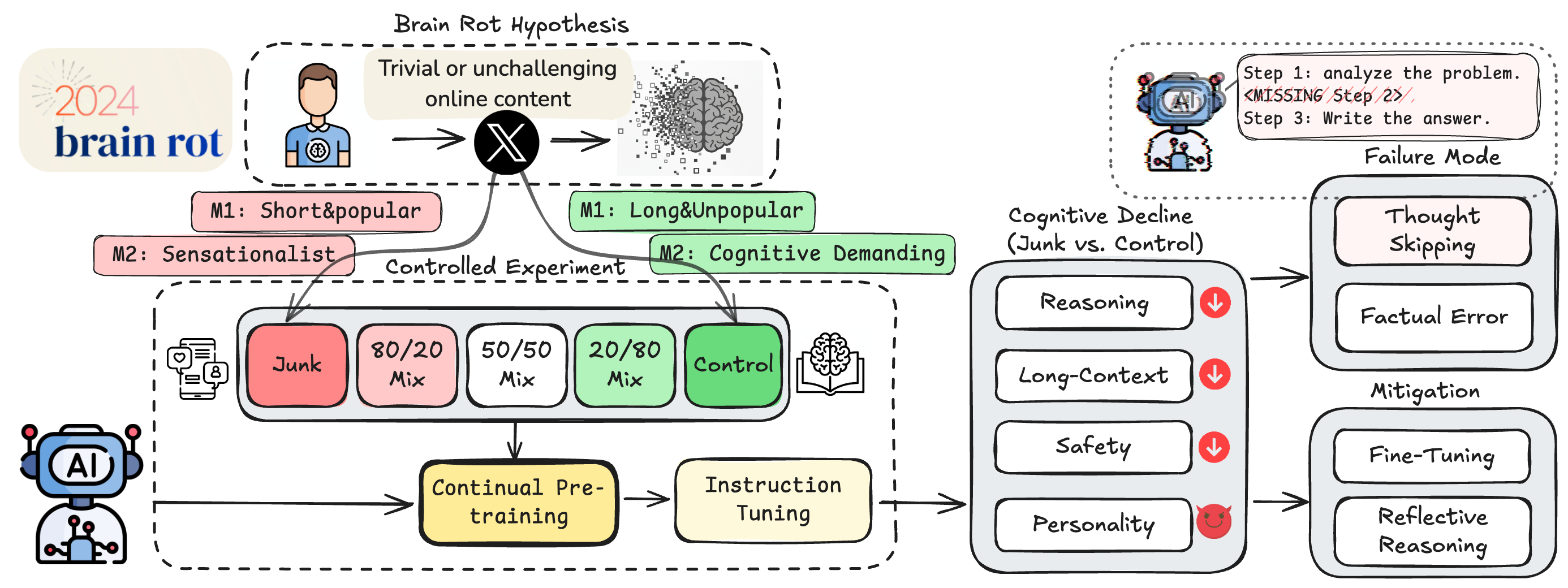
Research Shows LLMs Develop Cognitive Degradation from Social Media Training Data
This research paper introduces the concept of 'LLM Brain Rot' - a phenomenon where large language models (LLMs) experience cognitive degrada

Lumina-DiMOO: Open-Source Multimodal AI Model Using Discrete Diffusion for Cross-Modal Generation
Lumina-DiMOO is an open-source foundational model that uses discrete diffusion modeling for multimodal generation and understanding across v

Efficient Training of Diffusion Models with Token Routing (TREAD)
The article discusses TREAD, a novel method for improving the training efficiency and generative performance of diffusion models, which are