Using Curriculum Learning and PufferLib to Train Superhuman AI Agents for 2048 and Tetris
By
a1k0n
Master baker tier. Every paragraph earns its place on the tray.
Summary
The article describes using PufferLib, a reinforcement learning framework, to train gaming agents that achieve superhuman performance in 2048 and Tetris. The author details how curriculum learning (gradually increasing difficulty) and Pareto sweeps (systematic hyperparameter optimization) enabled a 15MB policy to beat massive search-based solutions in 2048 after just 75 minutes of training. The article also discusses discovering that bugs in Tetris can become features for AI agents, and emphasizes the importance of speed, iteration, and systematic experimentation in reinforcement learning research.
Key quotes
· 5 pulledPufferLib allows anyone with a gaming computer to play the RL game, but getting from 'pretty good' to 'superhuman' requires tweaking every lever, repeatedly.
This is the story of how I trained agents that beat massive (few-TB) search-based solutions on 2048 using a 15MB policy trained for 75 minutes and discovered that bugs can be features in Tetris.
Training gaming agents is an addictive game. A game of sleepless nights, grinds, explorations, sweeps, and prayers.
PufferLib's C-based environments run at 1M+ st
TLDR? PufferLib, Pareto sweeps, and curriculum learning.
You might also wanna read

Reflections on DwarfStar 4's rapid rise in local AI inference
The author reflects on the unexpected popularity of DwarfStar 4 (DS4), a local AI inference project. They attribute its success to the conve
antirez.com·1d agoReflections on DwarfStar 4's rapid rise in local AI inference
The author reflects on the unexpected popularity of DwarfStar 4 (DS4), a local AI inference project. They attribute its success to the conve
antirez.com·1d ago
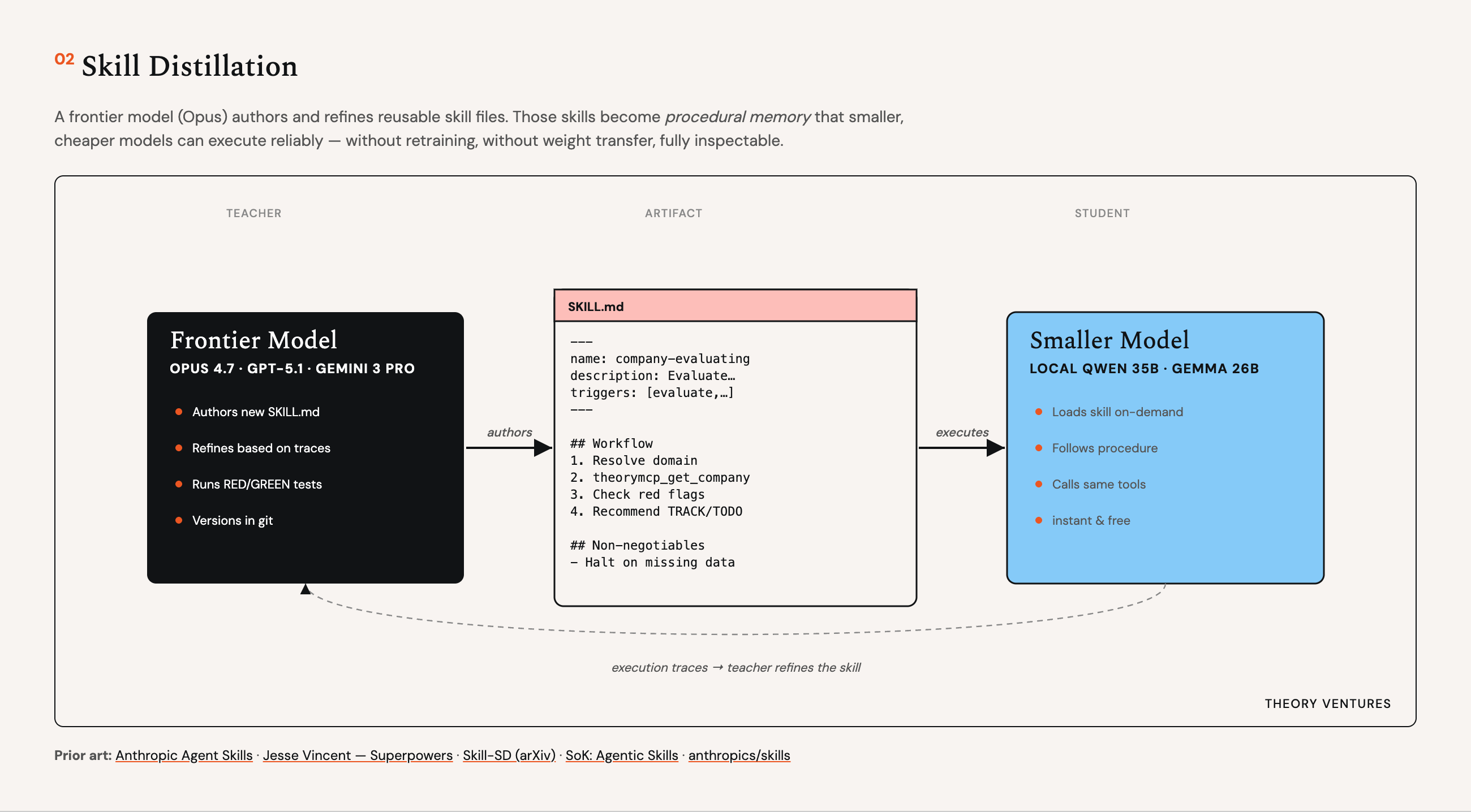
Building a Personal AI Agent with Markdown-Based Skills and Local Models
The article describes a personal AI agent built on Pi that manages the author's inbox, calendar, deal pipeline, blog publishing, and researc
 tomtunguz.com·2d ago
tomtunguz.com·2d ago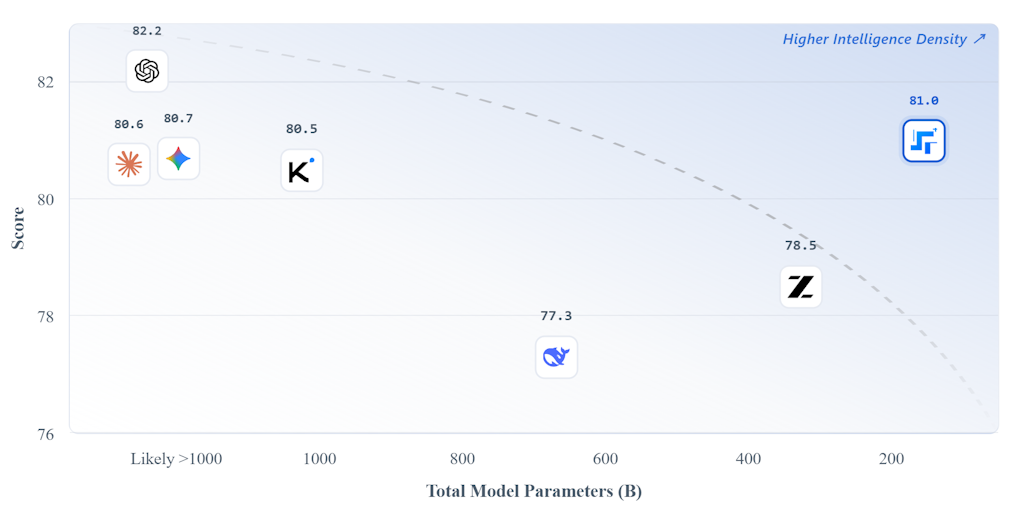
StepFun Releases Step 3.5 Flash: 196B Sparse MoE Model for OpenClaw Agents
StepFun has released Step 3.5 Flash, a 196B sparse Mixture of Experts (MoE) model that activates only 11B parameters per token for high effi
 Product Hunt·2d ago
Product Hunt·2d ago
Anthropic Releases Claude Opus 4.7 AI Model with 1M Context Window and Enhanced Coding Capabilities
Anthropic announces Claude Opus 4.7, their latest AI model featuring a hybrid reasoning architecture with a 1 million token context window.
 anthropic.com·2d ago
anthropic.com·2d agoAnthropic Releases Claude Opus 4.7 AI Model with 1M Context Window and Enhanced Coding Capabilities
Anthropic announces Claude Opus 4.7, their latest AI model featuring a hybrid reasoning architecture with a 1 million token context window.
anthropic.com·2d ago