NVIDIA launches Nemotron 3 Ultra, a 550B open-weight AI model for long-running enterprise agents
By
Shubham Sawarkar
Summary
NVIDIA has announced Nemotron 3 Ultra, a 550-billion-parameter open-weight Mixture-of-Experts language model (with 55 billion active parameters per token) designed specifically for long-running AI agents, tool-heavy workflows, coding copilots, research agents, and complex enterprise automations. The model positions NVIDIA as a competitor in the frontier-model space, moving beyond its traditional GPU hardware business into advanced AI software with an open-weight approach.
Source

 bskyNVIDIA launches Nemotron 3 Ultra, a 550B open-weight AI model for long-running enterprise agentsgadgetbond.com
bskyNVIDIA launches Nemotron 3 Ultra, a 550B open-weight AI model for long-running enterprise agentsgadgetbond.comKey quotes
· 3 pulledNVIDIA's new Nemotron 3 Ultra isn't just another big language model announcement; it's NVIDIA stepping squarely into the frontier-model arena with an open-weight system built from the ground up for long-running AI agents, not just chatbots.
It's a 550-billion-parameter Mixture-of-Experts model (with 55 billion parameters active at any given token) that NVIDIA is positioning as an open, high-speed reasoning engine for tooling-heavy workflows, coding copilots, research agents, and complex enterprise automations.
What makes Nemotron 3 Ultra interesting is not only its size, but what it represents — NVIDIA taking the company beyond GPUs and into true frontier-model territory.
You might also wanna read


Building Ultra-Low-Latency Voice Agents with NVIDIA Open Models
This technical guide demonstrates how to build ultra-low-latency voice agents using NVIDIA's open models, including the newly launched Nemot
 daily.co·5mo ago
daily.co·5mo ago
NVIDIA Open-Sources Cosmos 3 Foundation Model for Physical AI Reasoning and Action Generation
NVIDIA has released Cosmos 3, an open-source foundation model for Physical AI that integrates physical reasoning, world generation, and acti
 developer.nvidia.com·21d ago
developer.nvidia.com·21d ago
NVIDIA NemoClaw: Open Source Reference Stack for Secure OpenClaw Assistant Deployment
NVIDIA NemoClaw is an open source reference stack that simplifies running OpenClaw always-on assistants more securely by integrating with NV
 github.com·3mo ago
github.com·3mo ago
Jet-Nemotron: Hybrid Language Model Architecture with PostNAS Achieves High Efficiency and Accuracy
Jet-Nemotron is a new family of hybrid-architecture language models that achieves comparable or superior accuracy to leading models like Qwe
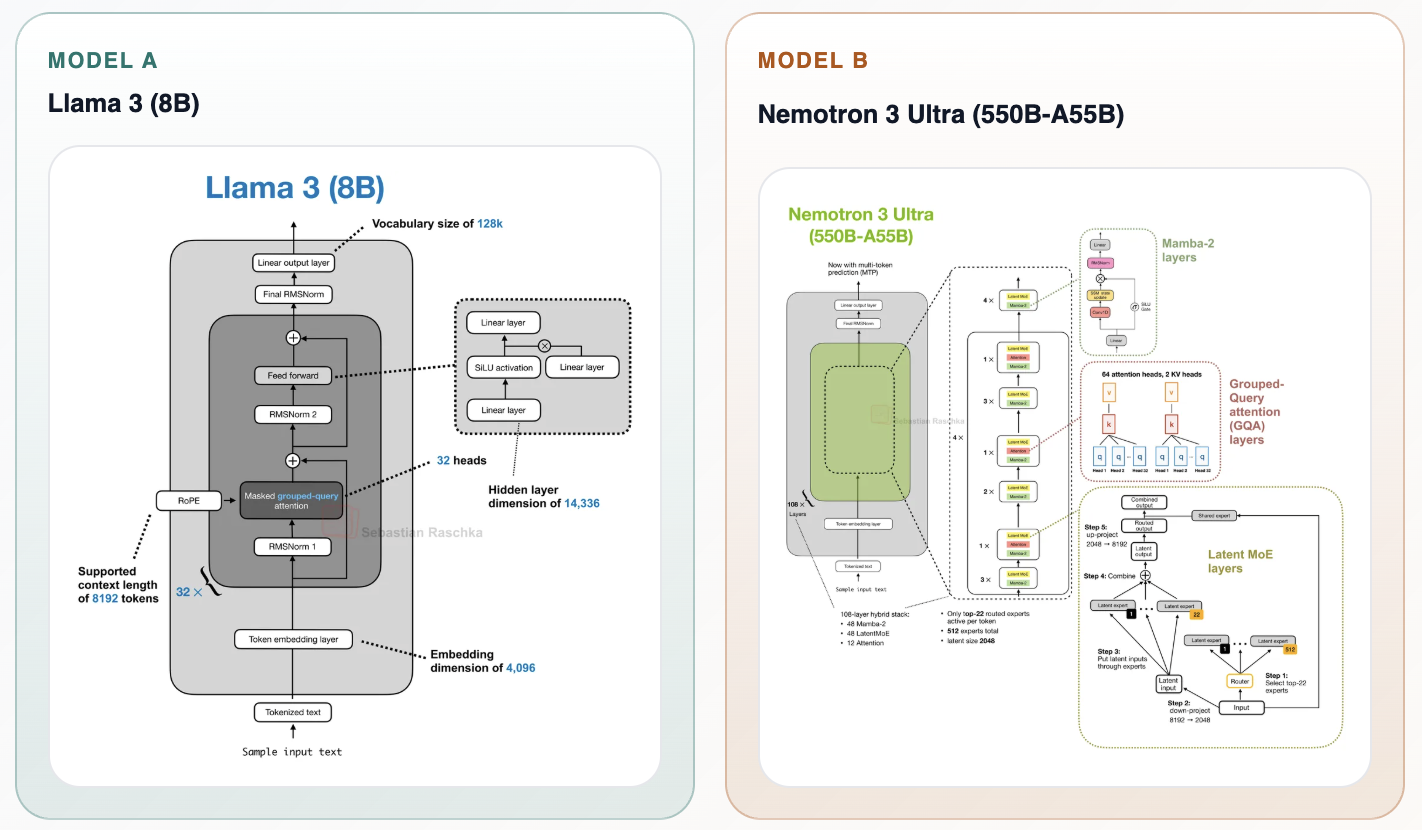
The growing complexity of modern LLM architectures: From Llama to Nemotron
The article discusses how LLM architectures have evolved from the clean, simple Transformer stacks of Llama (2022-2023) to much more complex

Unsloth and NVIDIA Partner to Accelerate LLM Fine-Tuning by 20%
Unsloth has partnered with NVIDIA to optimize fine-tuning of large language models, achieving 20% faster training speeds. The collaboration
Comments
Sign in to join the conversation.
No comments yet. Be the first.