The growing complexity of modern LLM architectures: From Llama to Nemotron
By
Ian
Summary
The article discusses how LLM architectures have evolved from the clean, simple Transformer stacks of Llama (2022-2023) to much more complex modern models like Nemotron 3 Ultra. It contrasts the straightforward LLM approach with the messy recommendation system graphs at Meta, noting that the industry has now made LLMs similarly complicated. The article references Seb Raschka's gallery of model architectures to compare Llama 3 and Nemotron 3 Ultra, and comments on how modern models use far more than just attention mechanisms.
Source
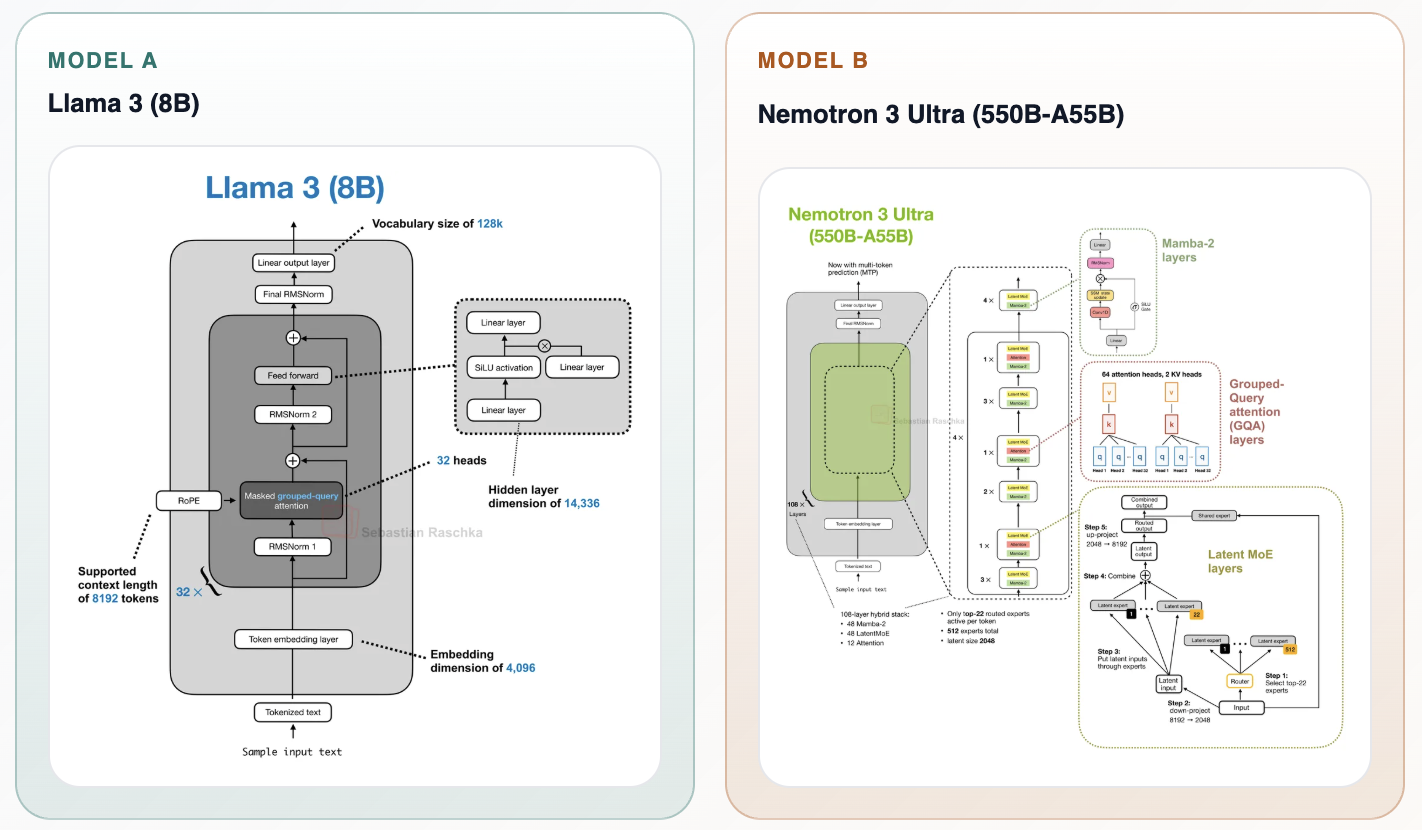
Key quotes
· 3 pulledThe LLM work that led to Llama was a clean, smooth stack of repeated Transformer modules; the recommendation systems graphs were, by contrast, terrifying.
Luckily, the industry has remedied that state of affairs by making LLMs a lot more complicated.
Attention might be all you need, but modern models certainly use a lot of
You might also wanna read


New Chinese AI models and Liquid Foundation Models push LLM efficiency and reasoning forward
The article discusses recent developments in language models, highlighting new Chinese models from StepFun and MiniMax that offer affordable
 heise.de·10d ago
heise.de·10d ago
Liquid AI Releases LFM2.5-8B-A1B Hybrid Model for On-Device Deployment
Liquid AI has released LFM2.5-8B-A1B, a new hybrid AI model family designed for on-device deployment. The model builds on the LFM2 architect
Ollama v0.7 Launches New Engine for Local Vision Model Execution
Ollama v0.7 introduces a new engine designed for running leading vision models locally, such as Llama 4 and Gemma 3. The update focuses on i
 Product Hunt·10mo ago
Product Hunt·10mo ago
How OpenClaw and AI agent harnesses are reshaping LLMs, inference, and CPU demand
The article discusses how AI agent harnesses like OpenClaw are transforming the LLM landscape by enabling models to automate complex tasks b
 theregister.com·20d ago
theregister.com·20d agoComments
Sign in to join the conversation.
No comments yet. Be the first.