Unsloth and NVIDIA Partner to Accelerate LLM Fine-Tuning by 20%
Learn how NVIDIA helped Unsloth to make fine-tuning AI models 20% faster with explanations and diagrams.
Read the full articleYou might also wanna read


Unsloth Dynamic NVFP4: A Guide to 4-Bit Inference on NVIDIA Blackwell GPUs
Learn how Unsloth Dynamic NVFP4 enables fast, accurate 4-bit inference on NVIDIA Blackwell GPUs.
 unsloth.ai·3d ago
unsloth.ai·3d agoUnsloth Dynamic NVFP4: A Guide to 4-Bit Inference on NVIDIA Blackwell GPUs
Learn how Unsloth Dynamic NVFP4 enables fast, accurate 4-bit inference on NVIDIA Blackwell GPUs.
unsloth.ai·3d ago
Modular: How to Beat Unsloth's CUDA Kernel Using Mojo—With Zero GPU Experience
How to Beat Unsloth's CUDA Kernel Using Mojo—With Zero GPU Experience
Accelerating AI: Unpacking Unsloth’s Revolutionary Qwen3.6 Release
In a significant leap forward for AI enthusiasts and practitioners, Unsloth has just released a cutting-edge version of their Qwen3.6 model.
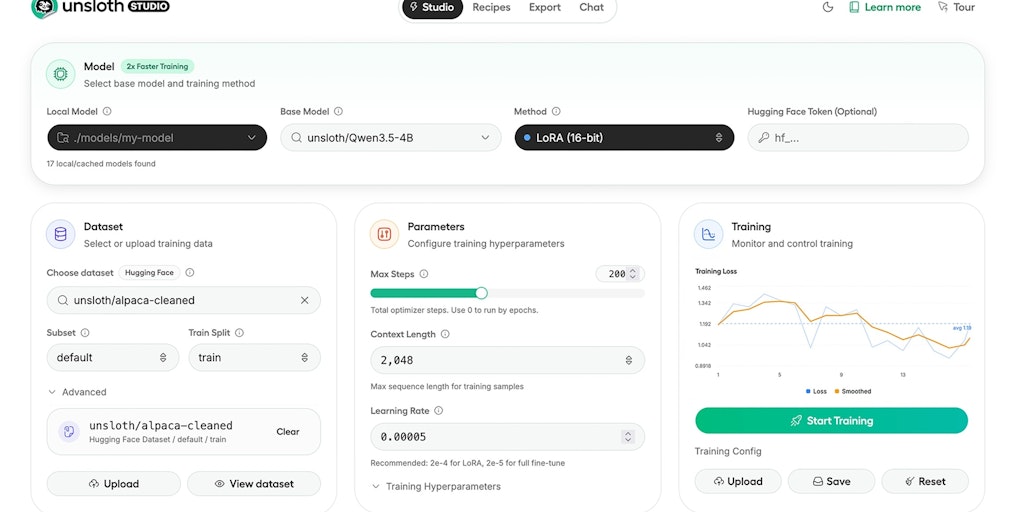
Unsloth: Open-Source Platform for Local AI Model Training and Inference
Open-source running and training of AI models and LLMs.
 Product Hunt·4mo ago
Product Hunt·4mo agoAre LLM-Generated GPU Kernels Production-Ready? A Trace-Driven Benchmark and Optimization Agent
arXiv:2607.14541v1 Announce Type: new Abstract: Existing GPU kernel generation benchmarks draw problems from synthetic or curated sources th

APEX4: Platform-Dependent W4A4 LLM Inference via Intra-SM Compute Rebalancing
W4A4 quantization promises full utilization of INT4 Tensor Cores, yet group dequantization overhead on CUDA Cores has driven existing system
Comments
Sign in to join the conversation.
No comments yet. Be the first.