Databricks Runtime 18: June 10, 2026
Source
MicrosoftDatabricks Runtime 18: June 10, 2026microsoft.comYou might also wanna read


Databricks Launches LTAP Architecture Unifying OLAP and OLTP on a Single Data Lake Copy
Databricks has launched LTAP (Lake Transactional/Analytical Processing), a new data architecture that unifies OLAP and OLTP workloads on a s
 databricks.com·18d ago
databricks.com·18d ago
Performance Benchmark: Polars vs DuckDB vs Daft vs Spark on 650GB Delta Lake Dataset
The article presents a performance comparison benchmark of four data processing frameworks (Polars, DuckDB, Daft, and Spark) on a 650GB Delt
 dataengineeringcentral.substack.com·7mo ago
dataengineeringcentral.substack.com·7mo ago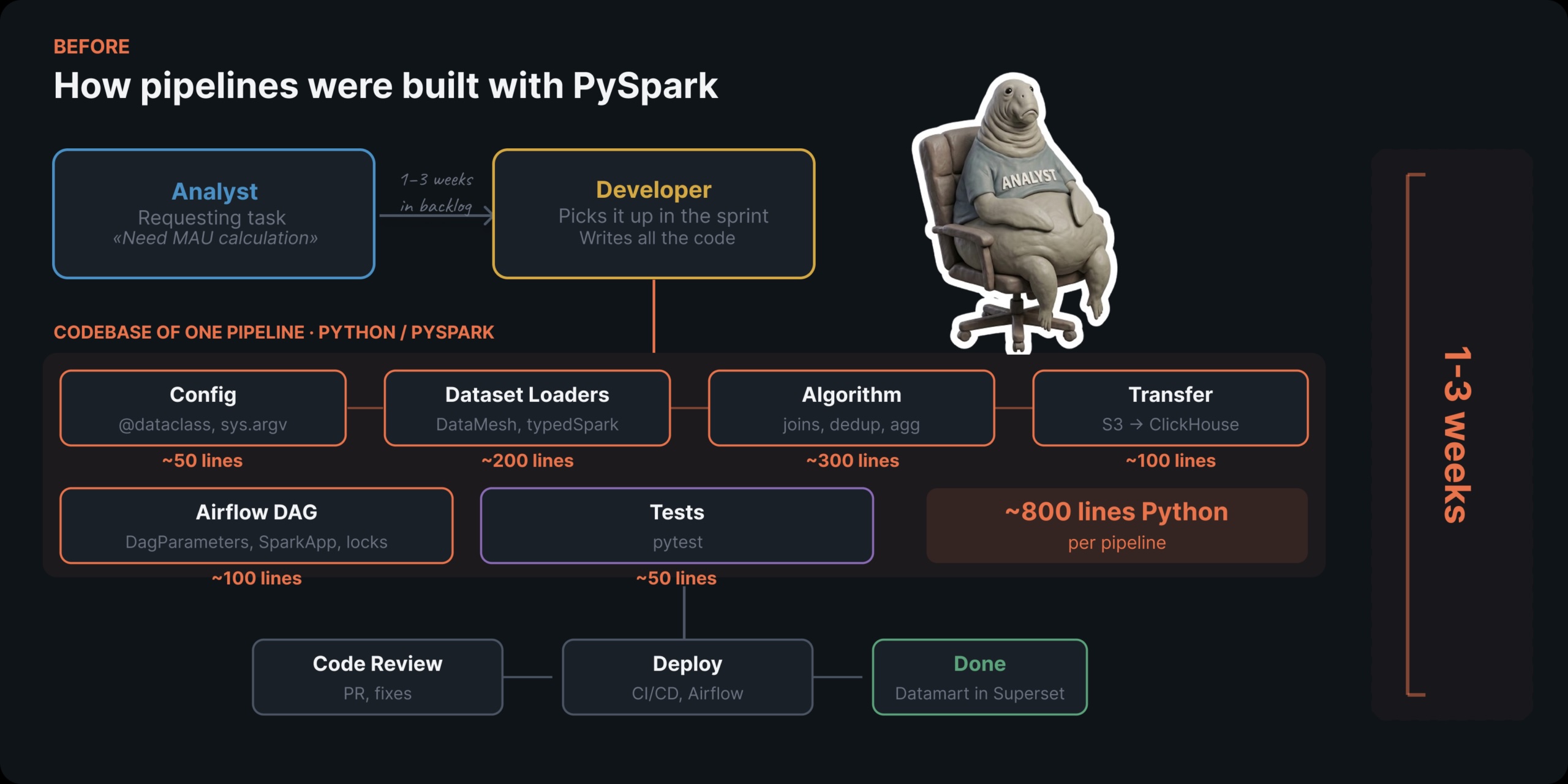
How Mindbox replaced PySpark with YAML-based pipelines using dlt, dbt, and Trino
Data engineer Kiril Kazlou describes how Mindbox replaced PySpark-based data pipelines with a stack using dlt, dbt, and Trino, configured th
 towardsdatascience.com·1mo ago
towardsdatascience.com·1mo ago
WarpStream Tableflow: Converting Kafka Data to Iceberg Tables with Low Latency
WarpStream Tableflow is a new product that addresses the challenges of converting Kafka topic data into Apache Iceberg tables. The article a
 warpstream.com·9mo ago
warpstream.com·9mo ago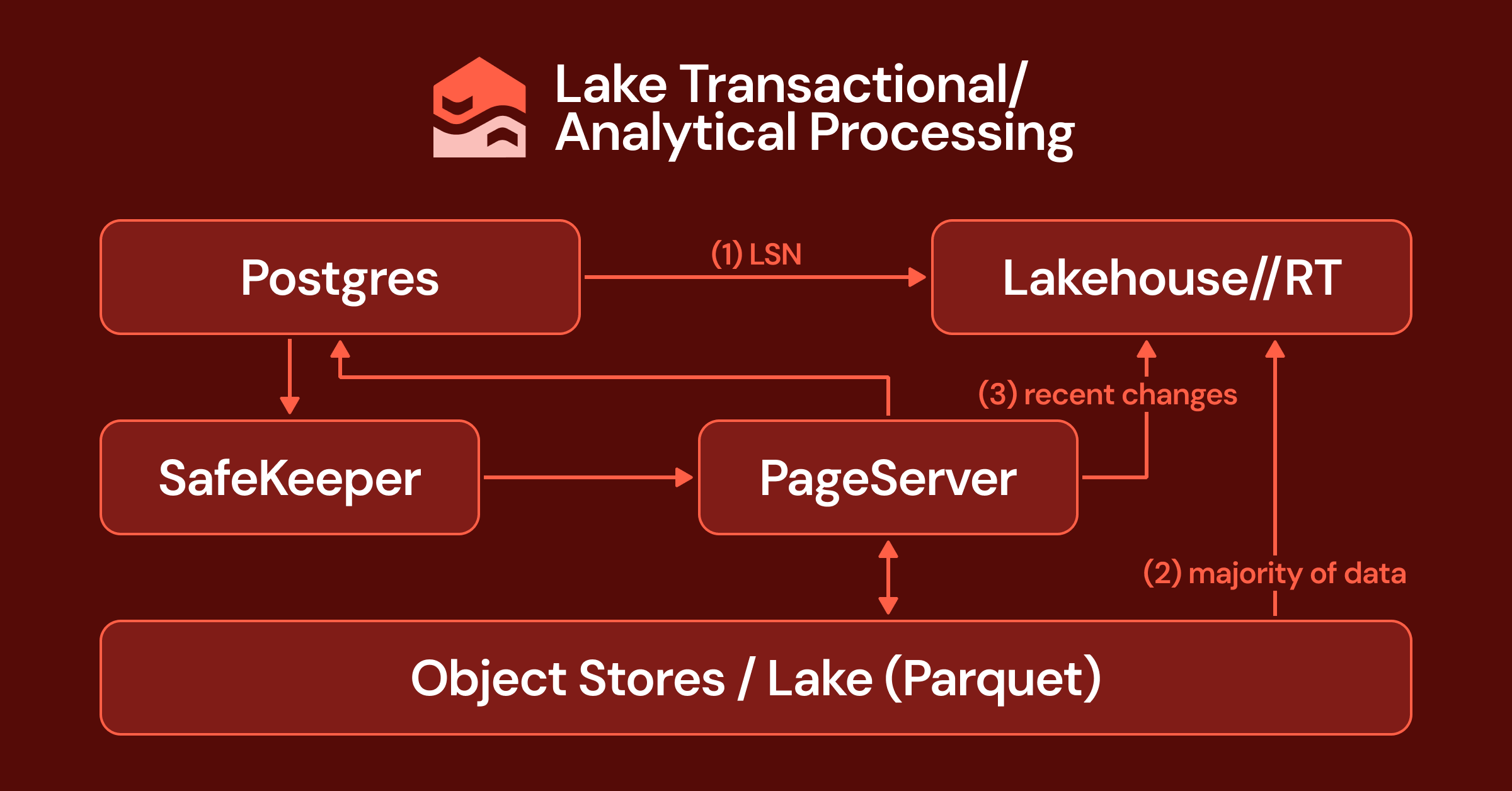
Rethinking database architecture: From monolithic storage to Lakebase and LTAP
The article discusses the evolution of database architecture, starting from the author's PhD experience at UC Berkeley where OLTP databases
 databricks.com·4d ago
databricks.com·4d agoRethinking database architecture: From monolithic storage to Lakebase and LTAP
The article discusses the evolution of database architecture, starting from the author's PhD experience at UC Berkeley where OLTP databases
databricks.com·4d ago
Snowflake, Databricks, and Azure Ship Postgres-Compatible Databases with Custom Storage Engines
Three major cloud data platforms — Snowflake, Databricks, and Microsoft Azure — have all recently shipped Postgres-compatible databases with
Comments
Sign in to join the conversation.
No comments yet. Be the first.