Databricks Launches LTAP Architecture Unifying OLAP and OLTP on a Single Data Lake Copy
By
@databricks
A five-star bake. Worth schmearing, sharing, saving.
Summary
Databricks has launched LTAP (Lake Transactional/Analytical Processing), a new data architecture that unifies OLAP and OLTP workloads on a single copy of data in the data lake, eliminating the need for ETL processes, data replicas, and separate pipelines. The foundation of this architecture is Lakebase, a serverless Postgres solution on open object storage that now serves thousands of customers and handles 12 million database launches per day. Databricks positions itself as the first LTAP platform, combining Lakebase with the Lakehouse under a unified governance model and storage layer for all operational and analytical workloads.
Key quotes
· 3 pulledDatabricks today launched LTAP (Lake Transactional/Analytical Processing), a new data processing architecture that unifies OLAP and OLTP on a single copy of data in the lake, eliminating ETL, replicas, and pipelines by design.
Lakebase, the foundation of the LTAP architecture, now serves thousands of customers and handles 12 million database launches per day across the platform.
Databricks is the world's first LTAP platform.
You might also wanna read


Databricks launches OpenSharing protocol as Linux Foundation project for AI model and data sharing
Databricks launched OpenSharing, the successor to its open-source Delta Sharing protocol, now a standalone Linux Foundation project. OpenSha
 bit.ly·2d ago
bit.ly·2d ago
Databricks Ships Iceberg v3 as Format War Ends; Competition Moves to Catalog and Optimizer Layers
Databricks shipped Apache Iceberg v3 to general availability, and CEO Ali Ghodsi declared that Delta Lake and Iceberg are now very close in
 shashi.co·17d ago
shashi.co·17d ago
lakeFS launches agentic AI data service with sandboxed governance for autonomous workloads
The article discusses how the data services industry is shifting focus toward automating data governance for agentic AI workloads. As AI age
bit.ly·3d ago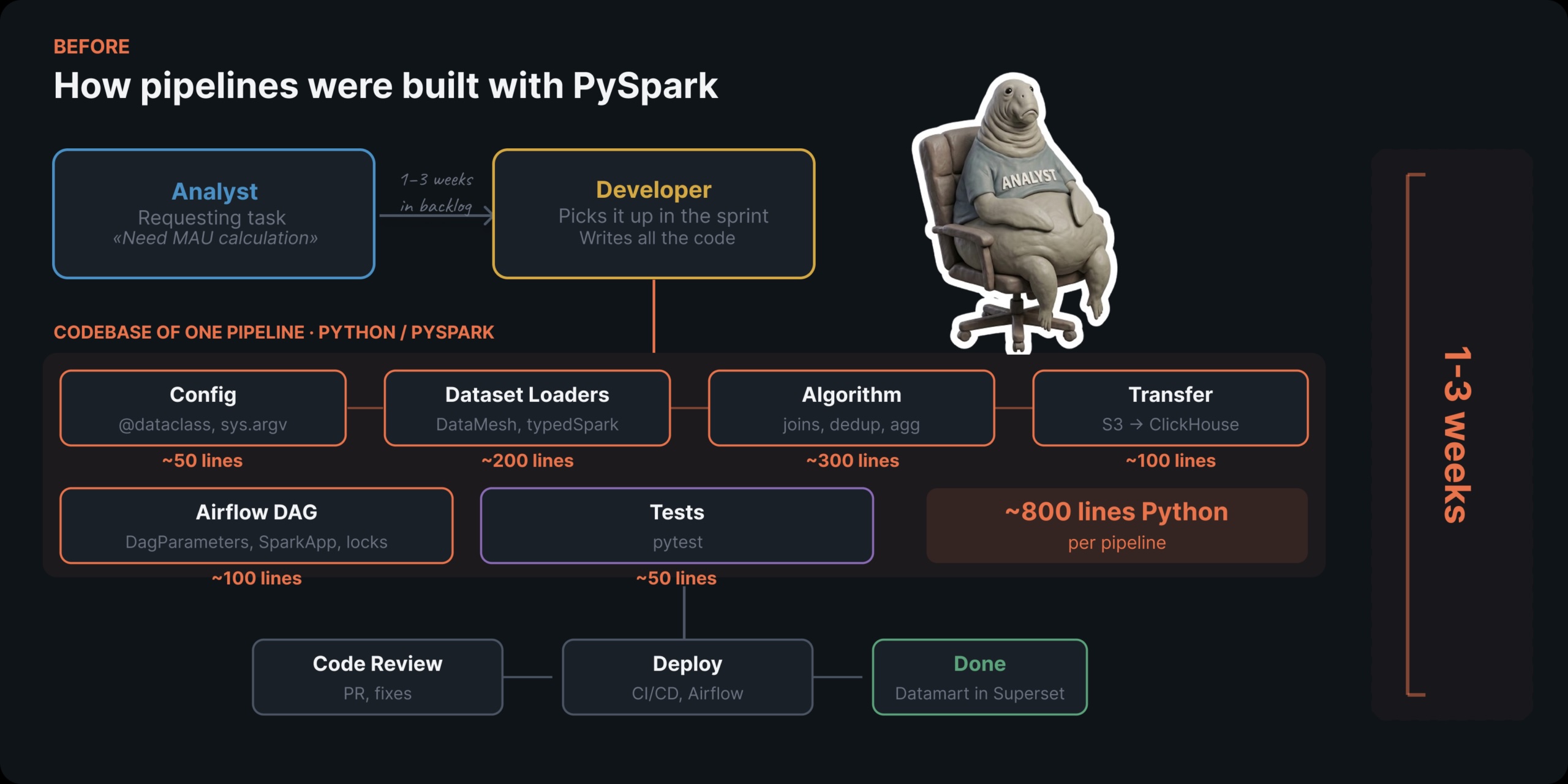
How Mindbox replaced PySpark with YAML-based pipelines using dlt, dbt, and Trino
Data engineer Kiril Kazlou describes how Mindbox replaced PySpark-based data pipelines with a stack using dlt, dbt, and Trino, configured th
 towardsdatascience.com·19d ago
towardsdatascience.com·19d ago
PySpark for Beginners: A Guide to Distributed Data Processing and Your First DataFrame
A beginner-friendly guide to PySpark, covering the transition from pandas to distributed computing with Spark. The article explains what PyS
towardsdatascience.com·2d ago
Databricks Launches Genie One, Genie Agents, and Genie Ontology for Enterprise AI Workflows
Databricks has announced three new AI offerings—Genie One, Genie Agents, and Genie Ontology—designed to bridge the gap between raw data and
 startuphub.ai·9h ago
startuphub.ai·9h ago