CursorBench 3.1: Benchmarking AI Coding Agents on Real-World Multi-File Tasks
By
handfuloflight
Summary
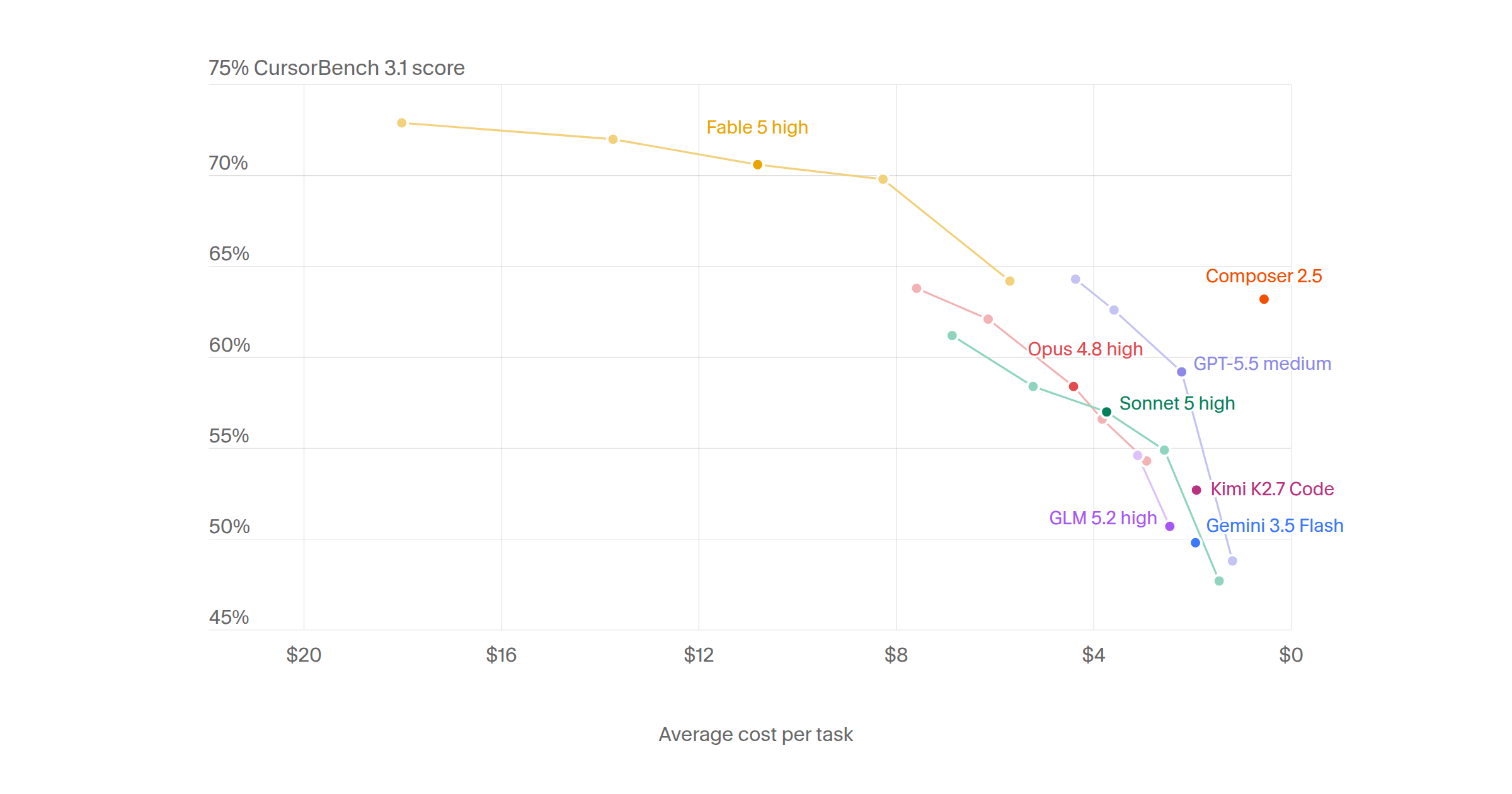
CursorBench is a benchmark developed by Cursor to evaluate AI coding agents on ambiguous, multi-file tasks drawn from real Cursor sessions. The article presents CursorBench 3.1 results comparing various models (Fable 5, Opus 4.8, GPT-5.5, Sonnet 5, etc.) on their performance scores versus average cost per task. Fable 5 Max leads with a 72.9% score at $18.02 per task, while other Fable 5 variants and models show varying cost-performance tradeoffs. The benchmark aims to measure how well agents handle realistic, messy coding scenarios.
Source
 Hacker NewsCursorBench 3.1: Benchmarking AI Coding Agents on Real-World Multi-File Taskscursor.com
Hacker NewsCursorBench 3.1: Benchmarking AI Coding Agents on Real-World Multi-File Taskscursor.comKey quotes
· 3 pulledWe evaluate agents on ambiguous, multi-file tasks from real Cursor sessions.
Higher scores are better.
A scatter and line chart comparing Fable 5, Opus 4.8, Opus 4.7, GPT-5.5, Sonnet 5, Sonnet 4.6, GLM 5.2, Composer 2.5, and Composer 2 scores against average cost per task.
You might also wanna read

Cursor, Codex, and Claude Code compared: Which AI coding assistant actually boosts developer speed
A tech writer compares three AI coding assistants — Cursor, Codex (GitHub Copilot), and Claude Code — over a 30-day trial period. The articl
 xda-developers.com·1mo ago
xda-developers.com·1mo ago
New benchmark reveals top AI models solve only 3% of realistic knowledge work tasks
A new benchmark called AA-Briefcase from Artificial Analysis tests AI models on realistic, multi-week knowledge work projects using fragment
 the-decoder.com·12d ago
the-decoder.com·12d ago
Cursor: AI-Powered Code Editor for Enhanced Developer Productivity
Cursor is an AI-powered code editor designed to significantly boost developer productivity by integrating artificial intelligence directly i
 Product Hunt·1y ago
Product Hunt·1y ago
Cursor: AI-Powered Code Editor for Enhanced Developer Productivity
Cursor is an AI-powered code editor designed to significantly boost developer productivity by integrating AI assistance directly into the co
Product Hunt·1mo ago
ParseBench — Document Parsing Benchmark for AI Agents
parsebench.ai·7d ago
Benchmarking GLM-5.2 vs Opus 4.8: Long-context retrieval performance for coding agents
This article benchmarks GLM-5.2 (an open-source model from Z.ai) against Anthropic's Opus 4.8 for long-context retrieval in coding agent use
Comments
Sign in to join the conversation.
No comments yet. Be the first.