New benchmark reveals top AI models solve only 3% of realistic knowledge work tasks
By
Maximilian Schreiner
Summary
A new benchmark called AA-Briefcase from Artificial Analysis tests AI models on realistic, multi-week knowledge work projects using fragmented source files like Slack threads, emails, meeting transcripts, and data exports. The top-performing model, Claude Fable 5, fully solves only 3 percent of tasks, and on 31 out of 91 tasks, no model achieves even a 50 percent pass rate. The results highlight how far AI still has to go in handling complex, real-world knowledge work.
Source

 bskyNew benchmark reveals top AI models solve only 3% of realistic knowledge work tasksthe-decoder.com
bskyNew benchmark reveals top AI models solve only 3% of realistic knowledge work tasksthe-decoder.comKey quotes
· 3 pulledEven the best AI model fails at realistic knowledge work, fully solving just 3 percent of tasks.
The top performer, Claude Fable 5, hits the highest rubric pass rate but still nails all criteria on just 3 percent of tasks.
On 31 out of 91 tasks, no model even clears 50 percent.
You might also wanna read


Claude Fable 5 benchmarks show middling results with 19% security pass rate but four unprecedented solves
An analysis of Anthropic's Claude Fable 5 (Mythos-class model) benchmarked on 200 real-world vulnerability-fixing tasks. Despite high launch
 endorlabs.com·8d ago
endorlabs.com·8d ago
SkillsBench: A Benchmark for Evaluating AI Agent Skills Across Diverse Tasks
SkillsBench is a new benchmark for evaluating how well AI agent skills work across diverse tasks. The benchmark includes 86 tasks across 11

AI Model Benchmark: The Evolution from Zero-Shot to Agentic Approaches for Creative Tasks
The article discusses Simon Willison's informal benchmark test for AI models: generating an SVG image of a pelican riding a bicycle. This se
 robert-glaser.de·7mo ago
robert-glaser.de·7mo ago
Hands-on with Claude Fable 5: A relentlessly proactive AI coding assistant
The article describes the author's hands-on experience with Claude Fable 5, an AI coding assistant that is described as "relentlessly proact
Hands-on with Claude Fable 5: A relentlessly proactive AI coding assistant
The article describes the author's hands-on experience with Claude Fable 5, an AI coding assistant that is described as "relentlessly proact

Assessing the Real-World Impact of AI on Open-Source Developer Productivity in Early 2025
This article examines the limitations of current AI coding benchmarks, arguing that they sacrifice realism for scale and efficiency. Benchma
 metr.org·11mo ago
metr.org·11mo ago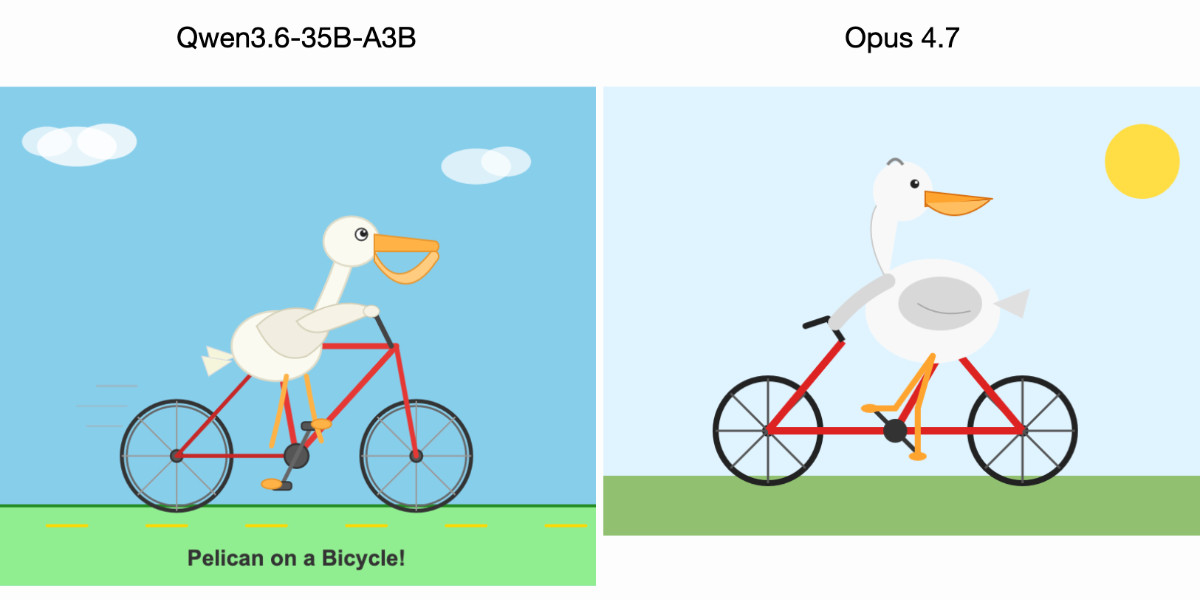
Benchmark Comparison: Qwen3.6-35B-A3B Outperforms Claude Opus 4.7 in Pelican Image Generation Test
The article presents a comparative benchmark test between two AI language models - Qwen3.6-35B-A3B from Alibaba and Claude Opus 4.7 from Ant