Benchmarking GLM-5.2 vs Opus 4.8: Long-context retrieval performance for coding agents
By
Braintrust Team
Summary
This article benchmarks GLM-5.2 (an open-source model from Z.ai) against Anthropic's Opus 4.8 for long-context retrieval in coding agent use cases. Using a Braintrust-native evaluation framework, the authors test both models on exact retrieval from long contexts, comparing performance, cost, and latency. The findings show that GLM-5.2 approaches Opus 4.8's retrieval accuracy while offering significant advantages in cost efficiency and the ability to run native inference locally, making it a compelling option for teams building agent-based products.
Source
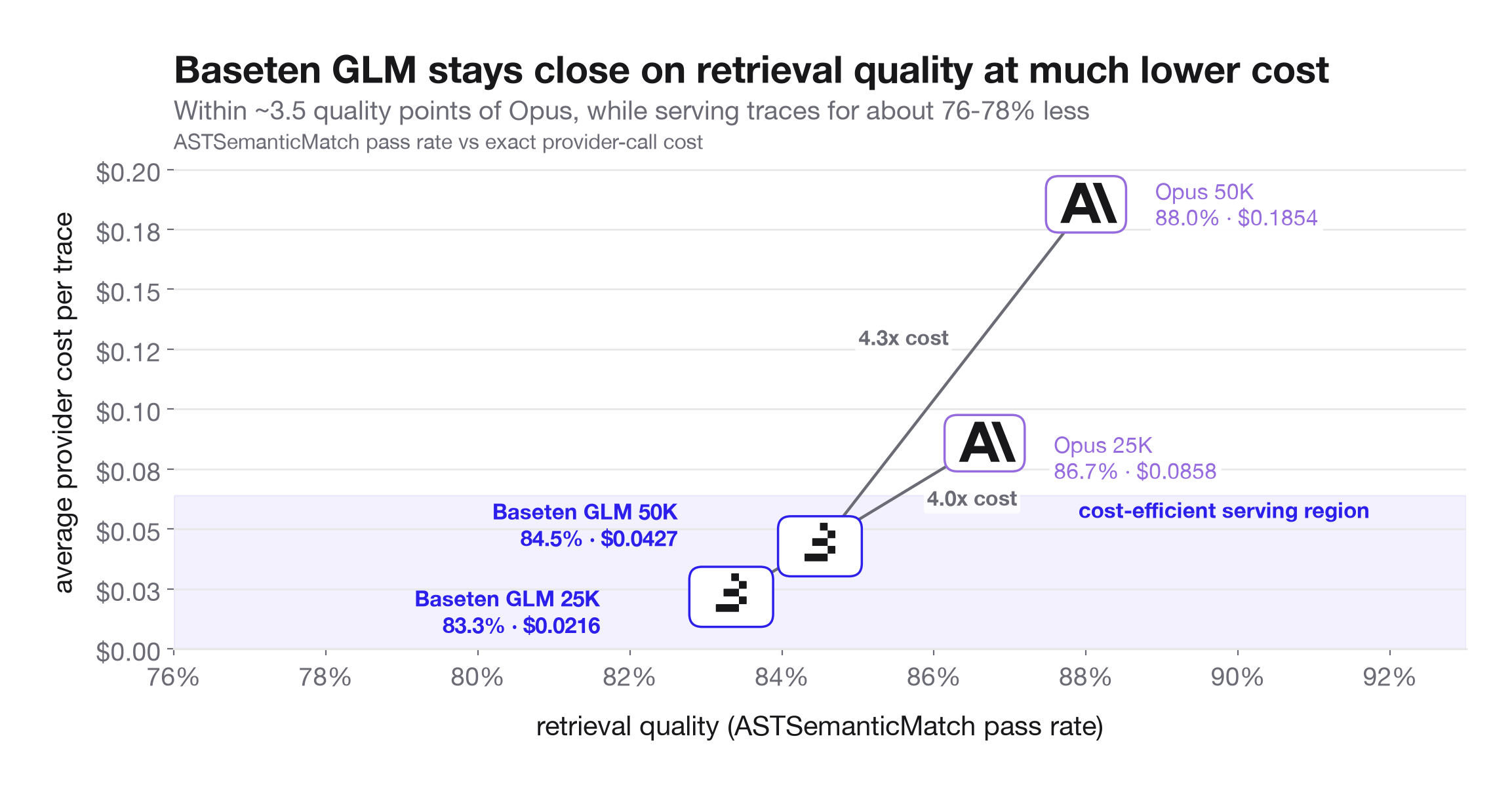
Key quotes
· 3 pulledFor an LLM to be useful for coding agents, it must be able to accurately retrieve information from long context.
GLM-5.2 from Z.ai has shown that it can perform well as a coding agent that manages long context retrieval.
Because it is open-source, it can be used to support native inference for teams building agent-based products.
You might also wanna read


Snowflake benchmark: China's GLM-5.2 nearly matches Claude Opus 4.7 on coding tasks at a fraction of the cost
Snowflake benchmarked Zhipu AI's GLM-5.2 against Anthropic's Claude Opus 4.7 across 103 coding tasks. The two models performed nearly neck-a
 the-decoder.com·5d ago
the-decoder.com·5d ago
Z.ai Launches GLM-5.2: A 1M-Token Context Model for Long-Horizon Tasks
Z.ai introduces GLM-5.2, their latest flagship AI model designed specifically for long-horizon tasks. The model delivers substantial improve
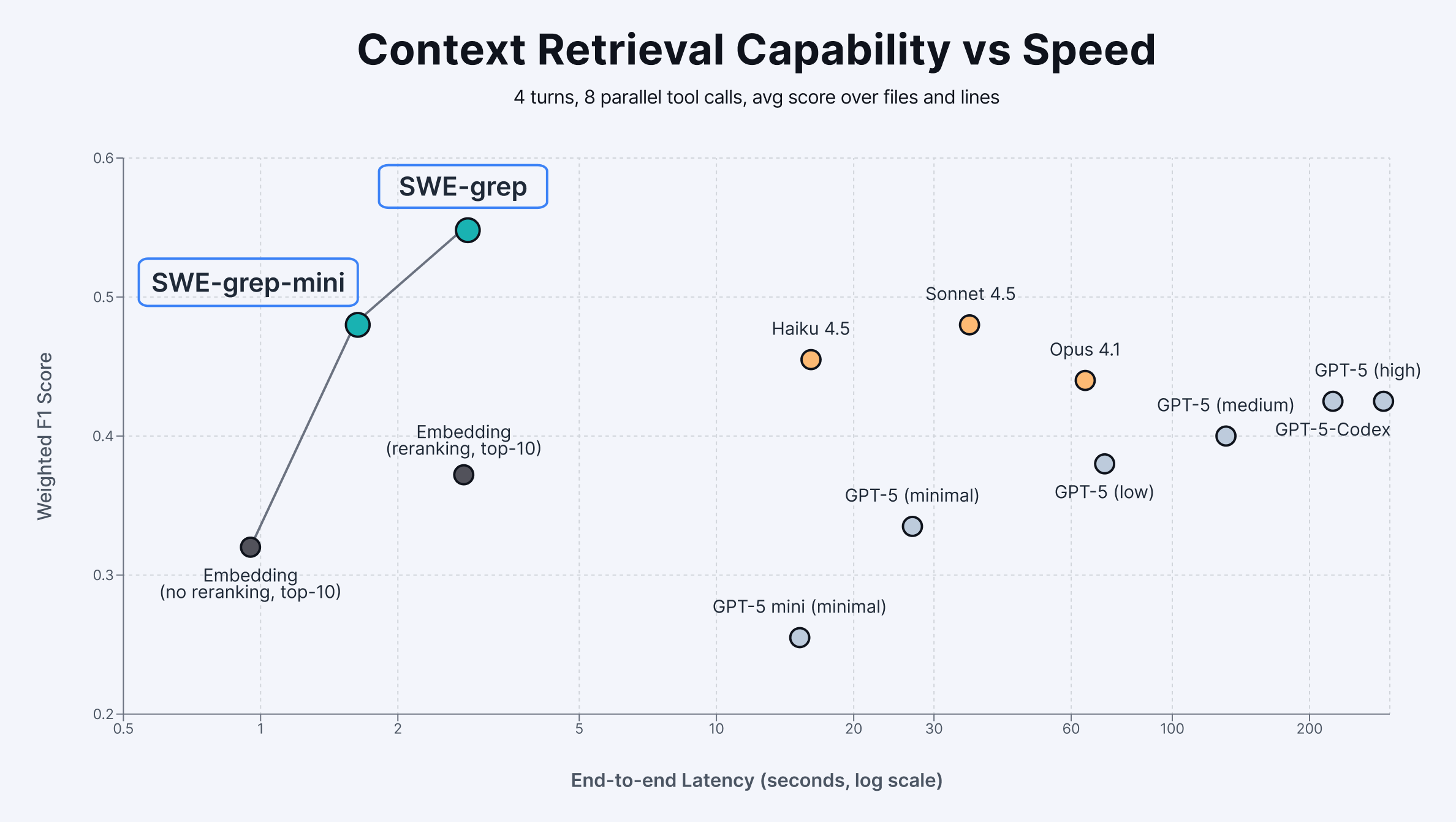
Cognition Releases SWE-grep and SWE-grep-mini: Fast AI Models for Context Retrieval in Coding
Cognition has developed SWE-grep and SWE-grep-mini, two specialized AI models designed for fast, parallel context retrieval in coding enviro
 cognition.ai·8mo ago
cognition.ai·8mo ago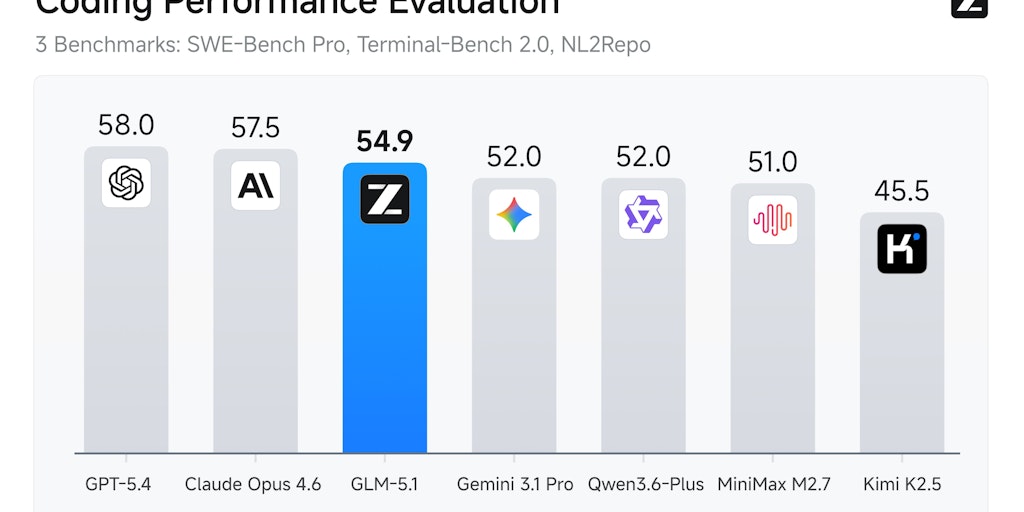
Z.ai Launches GLM-5.1 AI Model for Complex Agentic Coding Tasks
Z.ai has launched GLM-5.1, a next-generation AI model designed for complex agentic coding tasks. The model excels at long-horizon coding wor
 Product Hunt·3mo ago
Product Hunt·3mo ago
Z.ai launches GLM-5.2 with 1-million-token context window; MIT-licensed release coming next week
Z.ai has launched GLM-5.2, a new AI model featuring a massive 1-million-token context window. The model is set to be released under an MIT l

GLM-5.2 vs Claude Opus: A Head-to-Head Test Building a 3D WebGL Game
A comparison between the new open model GLM-5.2 and Claude Opus 4.8, testing them head-to-head on building a 3D platformer in raw WebGL. Whi
 techstackups.com·8d ago
techstackups.com·8d ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.