AI Randomness Experiments: Testing Language Models' Ability to Generate Random Names
By
benjismith
Crusty in the right places. Worth the chew.
Summary
This article describes experiments exploring how AI language models handle randomness, specifically testing Claude's ability to 'pick a name at random' across 37,500 trials with five different models and various prompt variations. Key findings include that 'Marcus' was the most common male name chosen (23.6% of the time), some parameter combinations produced perfectly deterministic outputs with zero entropy, and elaborate prompts increased unique names but introduced different biases. The research reveals systematic patterns in how AI models approach randomness tasks.
Key quotes
· 4 pulledThe most common male name was 'Marcus', chosen 4,367 times (23.6%)
Opus 4.5 returned 'Marcus' 100 out of 100 times with the simple prompt
Nine parameter combinations produced zero entropy — perfectly deterministic output
Elaborate prompts doubled unique names but introduced different biases
You might also wanna read


DeepSeek-V4: Hybrid Sparse-Attention Architecture Enables Efficient Million-Token Context Inference
DeepSeek-V4 introduces a hybrid sparse-attention architecture combined with on-policy distillation across domain specialists, enabling 1M-to
 artgor.medium.com·6h ago
artgor.medium.com·6h ago
Orthrus: A Dual-Architecture Framework for Fast, Lossless LLM Inference via Diffusion Decoding
Orthrus is a dual-architecture framework that combines autoregressive LLMs with diffusion models to enable fast, lossless parallel token gen
 github.com·16d ago
github.com·16d ago
Hybrid Attention Mechanism Achieves 51x Speedup in Language Model Inference
A developer has created a hybrid attention mechanism for language models by modifying PyTorch and Triton internals. The approach changes the
 news.ycombinator.com·1mo ago
news.ycombinator.com·1mo ago
Investigating the RYS Method: Testing Layer Duplication Across Modern LLMs
This article explores the RYS (Repeat Your Self) method discovered in Part 1, where duplicating seven middle layers in Qwen2-72B without wei
 dnhkng.github.io·2mo ago
dnhkng.github.io·2mo ago
Attention Residuals: A Drop-in Replacement for Standard Residual Connections in Transformers
Attention Residuals (AttnRes) is a novel architectural modification for Transformers that replaces standard residual connections with attent
github.com·2mo ago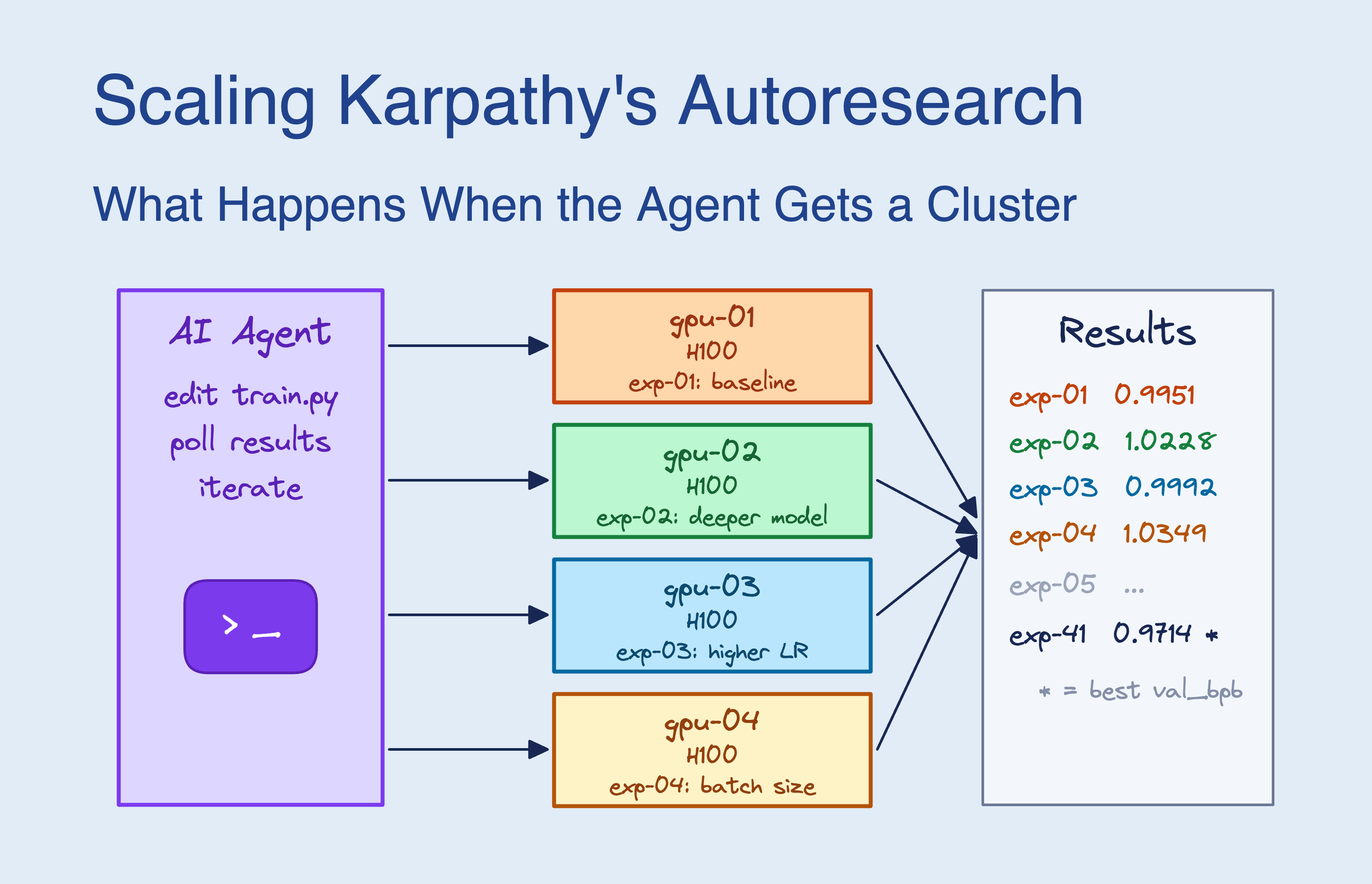
Scaling Karpathy's Autoresearch: Parallel GPU Processing Enables New AI Experimentation Strategies
The article describes an experiment where researchers scaled Andrej Karpathy's autoresearch system by giving it access to 16 GPUs on a Kuber
 blog.skypilot.co·2mo ago
blog.skypilot.co·2mo ago