Orthrus: A Dual-Architecture Framework for Fast, Lossless LLM Inference via Diffusion Decoding
By
FranckDernoncou
A five-star bake. Worth schmearing, sharing, saving.
Summary
Orthrus is a dual-architecture framework that combines autoregressive LLMs with diffusion models to enable fast, lossless parallel token generation. It uses a Qwen3 backbone and guarantees strictly lossless generation while achieving significant speedups (up to 4.25×). The project provides official implementation and model checkpoints for memory-efficient parallel token generation via dual-view diffusion decoding.
Key quotes
· 3 pulledOrthrus, a dual-architecture framework that unifies the exact generation fidelity of autoregressive Large Language Models (LLMs) with the high-speed parallel token generation of diffusion models.
All models use a Qwen3 backbone and guarantee strictly lossless generation.
Fast, lossless LLM inference via dual-view diffusion decoding.
You might also wanna read


DeepSeek-V4: Hybrid Sparse-Attention Architecture Enables Efficient Million-Token Context Inference
DeepSeek-V4 introduces a hybrid sparse-attention architecture combined with on-policy distillation across domain specialists, enabling 1M-to
 artgor.medium.com·7h ago
artgor.medium.com·7h ago
Hybrid Attention Mechanism Achieves 51x Speedup in Language Model Inference
A developer has created a hybrid attention mechanism for language models by modifying PyTorch and Triton internals. The approach changes the
 news.ycombinator.com·1mo ago
news.ycombinator.com·1mo ago
Investigating the RYS Method: Testing Layer Duplication Across Modern LLMs
This article explores the RYS (Repeat Your Self) method discovered in Part 1, where duplicating seven middle layers in Qwen2-72B without wei
 dnhkng.github.io·2mo ago
dnhkng.github.io·2mo ago
Attention Residuals: A Drop-in Replacement for Standard Residual Connections in Transformers
Attention Residuals (AttnRes) is a novel architectural modification for Transformers that replaces standard residual connections with attent
 github.com·2mo ago
github.com·2mo ago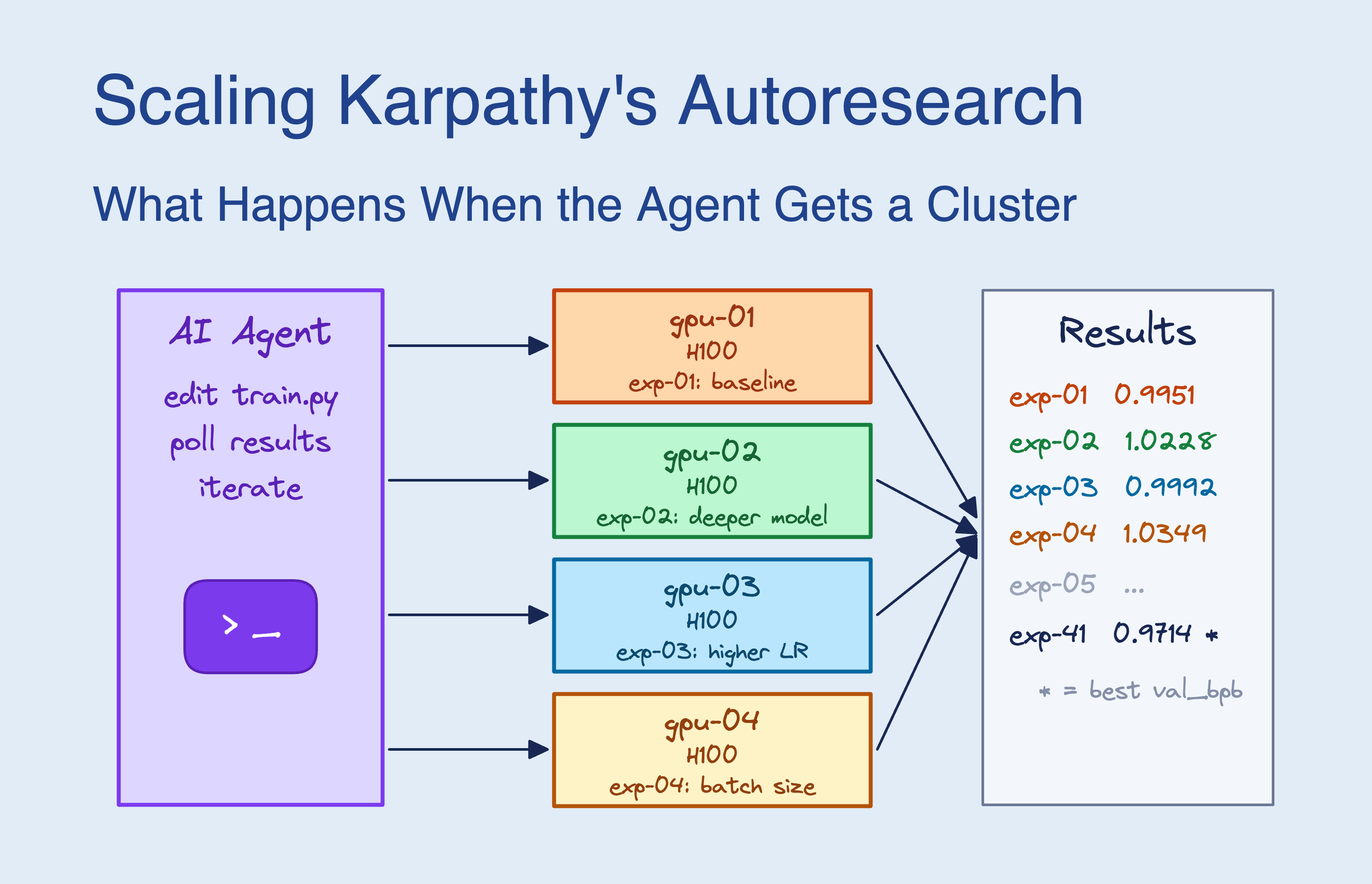
Scaling Karpathy's Autoresearch: Parallel GPU Processing Enables New AI Experimentation Strategies
The article describes an experiment where researchers scaled Andrej Karpathy's autoresearch system by giving it access to 16 GPUs on a Kuber
 blog.skypilot.co·2mo ago
blog.skypilot.co·2mo ago
LLM Circuit Finder: Duplicating Specific Layers in Transformer Models Improves Reasoning Performance Without Training
The article describes a GitHub project called 'llm-circuit-finder' that implements a method for discovering and exploiting 'reasoning circui
github.com·2mo ago