Investigating the RYS Method: Testing Layer Duplication Across Modern LLMs
By
realberkeaslan
The bagel they save for the regulars. Don't skim, savour.
Summary
This article explores the RYS (Repeat Your Self) method discovered in Part 1, where duplicating seven middle layers in Qwen2-72B without weight changes or training produced a top-performing model on the HuggingFace Open LLM Leaderboard. The author investigates whether this method is a general principle applicable to newer open-source models like Qwen3.5, MiniMax, and GLM-4.7, using mathematical probes and EQ-Bench testing on home compute resources. The research examines LLM neuroanatomy and hints at potential universal language patterns in large language models.
Key quotes
· 4 pulledThe method, which I called RYS (Repeat Your Self), was discovered using nothing but hard math probes and EQ-Bench on a pair of RTX 4090s.
So the question driving this post is simple: was RYS a fluke of Qwen2-72B, or is it a general principle?
In Part 1, I described how duplicating a block of seven middle layers in Qwen2-72B — no weight changes, no training — produced the #1 model on the HuggingFace Open LLM Leaderboard.
Since then, a flood of strong open-source models has arrived — Qwen3.5, MiniMax, GLM-4.7, and others — and I finally have enough compute at home to scan them properly.
You might also wanna read


DeepSeek-V4: Hybrid Sparse-Attention Architecture Enables Efficient Million-Token Context Inference
DeepSeek-V4 introduces a hybrid sparse-attention architecture combined with on-policy distillation across domain specialists, enabling 1M-to
 artgor.medium.com·6h ago
artgor.medium.com·6h ago
Orthrus: A Dual-Architecture Framework for Fast, Lossless LLM Inference via Diffusion Decoding
Orthrus is a dual-architecture framework that combines autoregressive LLMs with diffusion models to enable fast, lossless parallel token gen
 github.com·16d ago
github.com·16d ago
Hybrid Attention Mechanism Achieves 51x Speedup in Language Model Inference
A developer has created a hybrid attention mechanism for language models by modifying PyTorch and Triton internals. The approach changes the
 news.ycombinator.com·1mo ago
news.ycombinator.com·1mo ago
Attention Residuals: A Drop-in Replacement for Standard Residual Connections in Transformers
Attention Residuals (AttnRes) is a novel architectural modification for Transformers that replaces standard residual connections with attent
github.com·2mo ago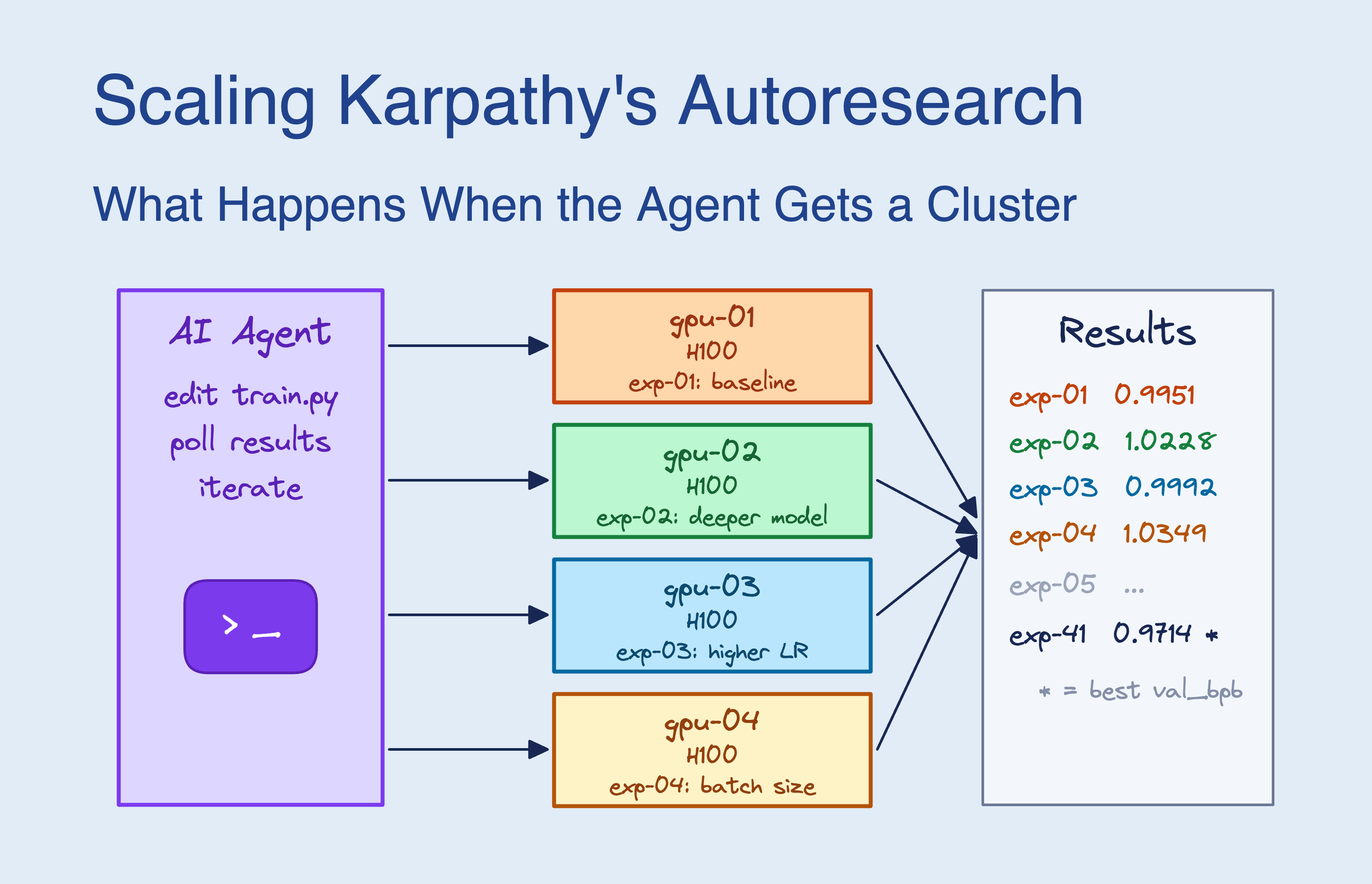
Scaling Karpathy's Autoresearch: Parallel GPU Processing Enables New AI Experimentation Strategies
The article describes an experiment where researchers scaled Andrej Karpathy's autoresearch system by giving it access to 16 GPUs on a Kuber
 blog.skypilot.co·2mo ago
blog.skypilot.co·2mo ago
LLM Circuit Finder: Duplicating Specific Layers in Transformer Models Improves Reasoning Performance Without Training
The article describes a GitHub project called 'llm-circuit-finder' that implements a method for discovering and exploiting 'reasoning circui
github.com·2mo ago