A deep technical dive into CUDA kernel execution: from source code to GPU warps
By
mezark
Summary
This article provides an in-depth technical walkthrough of what happens when a CUDA kernel (specifically a vector-add kernel) is executed. It traces the journey from the CUDA source code (nvcc compilation) all the way down to the hardware level where warps execute on GPU cores. The piece covers GPU architecture concepts like thread blocks, warps, memory hierarchy, and the CUDA execution model in meticulous detail.
Source

 Hacker NewsA deep technical dive into CUDA kernel execution: from source code to GPU warpsfergusfinn.com
Hacker NewsA deep technical dive into CUDA kernel execution: from source code to GPU warpsfergusfinn.comKey quotes
· 3 pulledHere's a simple CUDA program. It adds two vectors.
__global__ void vadd(const float* a, const float* b, float* c, int n) { int i = blockIdx.x * blockDim.x + threadIdx.x; if (i < n) c[i] = a[i] + b[i]; }
Tracing one vector-add kernel from nvcc all the way down to the warps that execute it.
You might also wanna read


Building a GPU backend for Emacs: A technical deep dive into hardware-accelerated text rendering
The author documents their personal journey of building a GPU-accelerated rendering backend for Emacs, driven by curiosity about why the edi
 en.andros.dev·3d ago
en.andros.dev·3d ago
AI-Driven Approach for Portable GPU Kernels in High-Performance Computing
This academic paper from North Carolina State University researchers presents an approach to leveraging AI ecosystems for creating portable
 hgpu.org·12d ago
hgpu.org·12d ago
cuTile Rust: Extending Rust's Ownership Model to Safe GPU Kernel Programming
This article presents cuTile Rust, a system that extends Rust's ownership and memory safety guarantees to GPU kernel programming. It allows

cuTile Rust: Extending Rust's Ownership Model to Safe GPU Kernel Programming
This paper (arXiv:2606.15991) presents cuTile Rust, a system that extends Rust's ownership and borrowing guarantees to GPU kernel authoring.
hgpu.org·12d ago
The Critical Role of GPU Kernel Quality in Machine Learning System Performance
This article discusses the critical role of GPU kernel quality in machine learning system performance. It highlights that end-to-end speed i
 mlc.ai·5d ago
mlc.ai·5d ago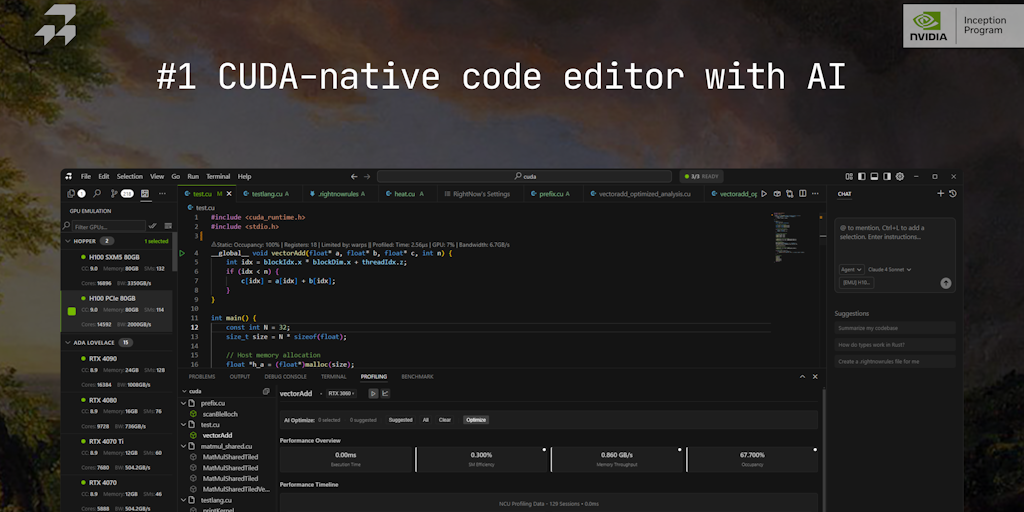
RightNow AI Launches First GPU-Native Code Editor with CUDA Support
RightNow AI has launched its fifth product - a GPU-native code editor that is the first CUDA-native development environment. The tool integr
 Product Hunt·5mo ago
Product Hunt·5mo ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.