Understanding Attention Sinks in Language Models and the StreamingLLM Solution
By
pr337h4m
Toasted golden, schmeared with insight. Top of the rack.
Summary
The article explains why language models fail in long conversations due to the removal of old tokens, leading to gibberish. It introduces the concept of 'attention sinks,' where models focus unused attention on the first few tokens. The solution, StreamingLLM, retains the first four tokens permanently while sliding the window for others, enabling stable processing of over 4 million tokens. This innovation is now integrated into platforms like HuggingFace, NVIDIA TensorRT-LLM, and OpenAI's latest models.
Key quotes
· 4 pulledWe discovered why language models catastrophically fail on long conversations: when old tokens are removed to save memory, models produce complete gibberish.
We found models dump massive attention onto the first few tokens as 'attention sinks'—places to park unused attention since softmax requires weights to sum to 1.
Our solution, StreamingLLM, simply keeps these first 4 tokens permanently while sliding the window for everything else, enabling stable processing of 4 million+ tokens instead of just thousands.
This mechanism is now in HuggingFace, NVIDIA TensorRT-LLM, and OpenAI's latest models.
You might also wanna read

Decoding AI's Internal Language: How Sparse Autoencoders Help Interpret Neural Activations
This article discusses how AI models like Claude process language through numerical activations, similar to neural activity in the human bra
 anthropic.com·24d ago
anthropic.com·24d ago
Nested Learning: A New Machine Learning Paradigm for Continual Learning Inspired by Human Neuroplasticity
The article introduces "Nested Learning," a new machine learning paradigm for continual learning that addresses the challenge of models acqu
 research.google·5mo ago
research.google·5mo ago
TabPFN-2.5: Next Generation Tabular Foundation Model Scales to 20× More Data Cells
TabPFN-2.5 is introduced as the next generation tabular foundation model that scales to 20× more data cells than its predecessor TabPFNv2. T

Binary Retrieval-Augmented Reward Method Reduces Language Model Hallucinations Without Performance Loss
Researchers propose a novel binary retrieval-augmented reward (RAR) method using online reinforcement learning to reduce hallucinations in l
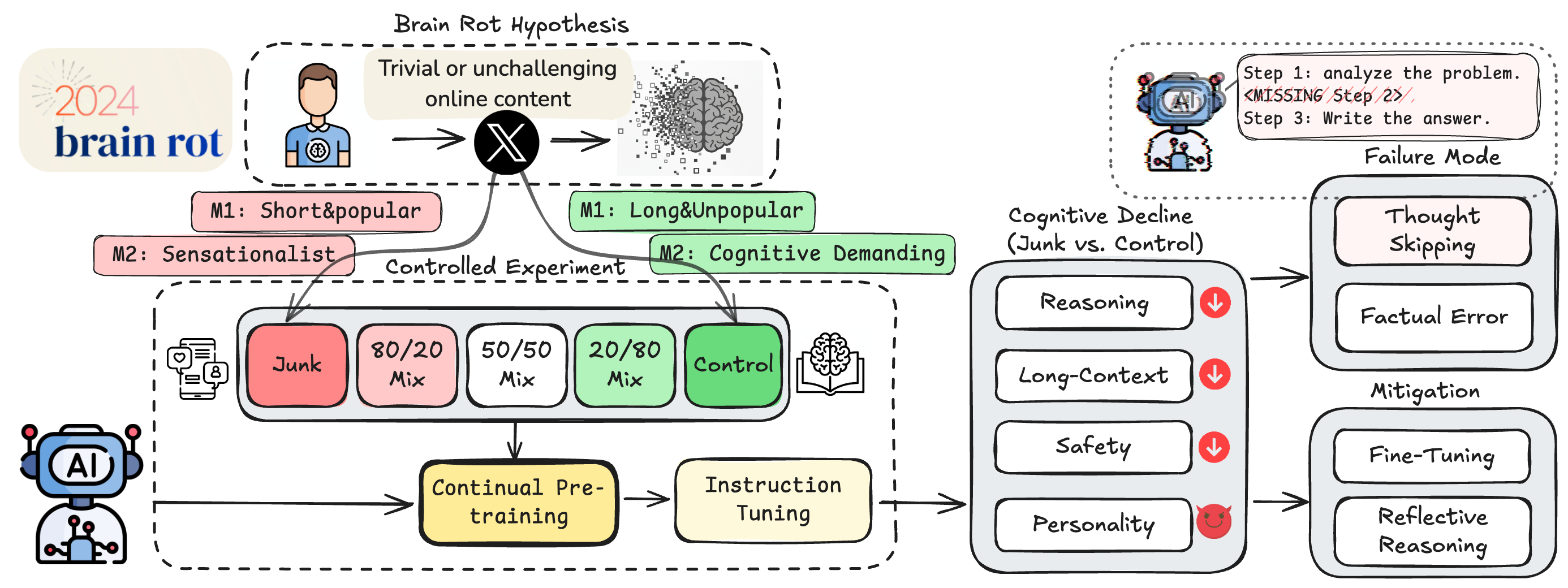
Research Shows LLMs Develop Cognitive Degradation from Social Media Training Data
This research paper introduces the concept of 'LLM Brain Rot' - a phenomenon where large language models (LLMs) experience cognitive degrada

Lumina-DiMOO: Open-Source Multimodal AI Model Using Discrete Diffusion for Cross-Modal Generation
Lumina-DiMOO is an open-source foundational model that uses discrete diffusion modeling for multimodal generation and understanding across v