Timber: AOT Compiler Converts Classical ML Models to Native C99 Code for High-Performance Inference
By
kossisoroyce
A baker's-dozen of insight crammed into one ring.
Summary
Timber is an open-source tool that compiles classical machine learning models (XGBoost, LightGBM, scikit-learn, CatBoost, ONNX) into native C99 inference code with zero runtime dependencies. It features an AOT (ahead-of-time) compiler that optimizes models and includes a built-in HTTP server with Ollama-compatible API for serving models. The tool claims 336x faster inference than Python and microsecond-level latency for single-sample inference.
Key quotes
· 4 pulledTimber takes a trained ML model — XGBoost, LightGBM, scikit-learn, CatBoost, ONNX (tree ensembles, linear models, SVMs), or a URDF robot description — runs it through a multi-pass optimizing compiler, and emits a self-contained C99 inference artifact with zero runtime dependencies.
A built-in HTTP server (Ollama-compatible API) lets you serve any model — local file or remote URL — in one command.
~2 µs single-sample inference
336x faster than Python inference
You might also wanna read


tinygrad: A Simple Neural Network Framework Based on Three Core Operation Types
The article introduces tinygrad, a neural network framework that simplifies complex networks into three fundamental operation types: Element
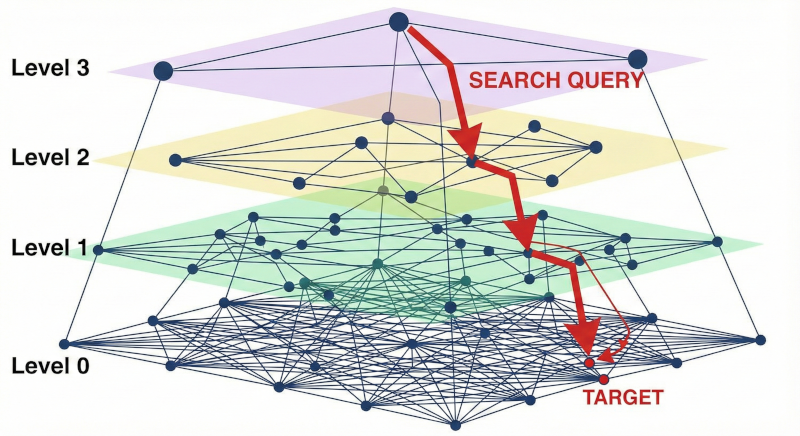
Implementing HNSW Algorithm for Vector Search in PHP: A Practical Guide
This article explains the Hierarchical Navigable Small World (HNSW) algorithm for efficient vector similarity search, contrasting it with br
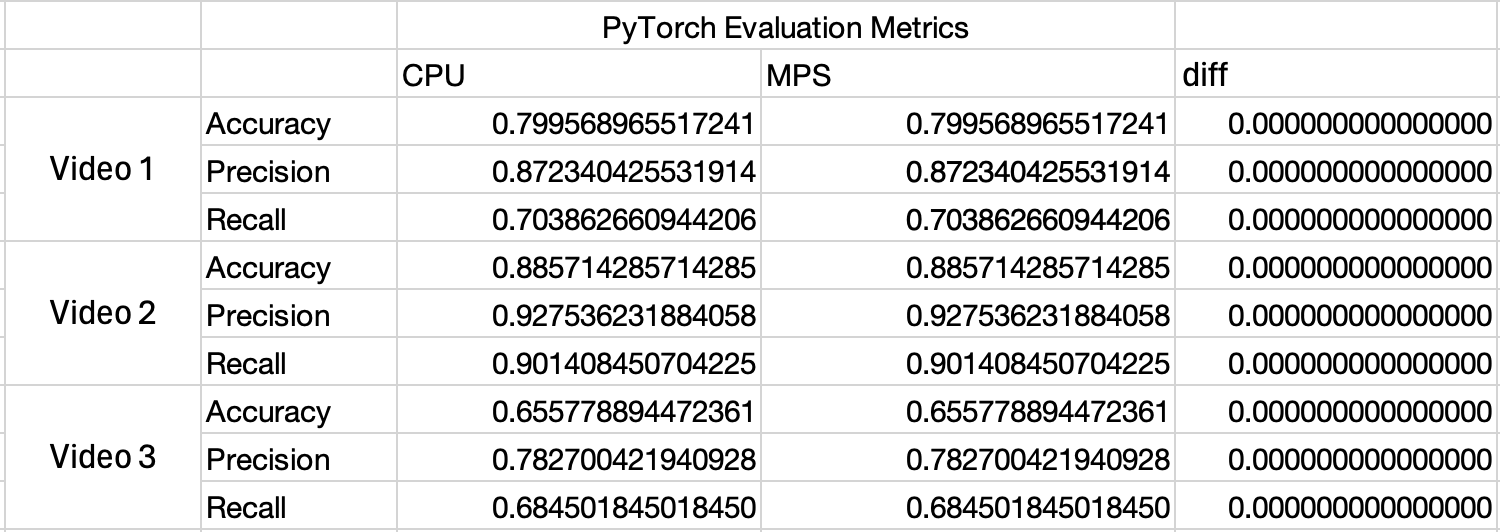
ONNX Runtime May Silently Convert Models to FP16 on Apple MPS Backend: Causes and Solutions
The article details a technical issue discovered in ONNX Runtime where models may be silently converted to FP16 (half-precision) when runnin
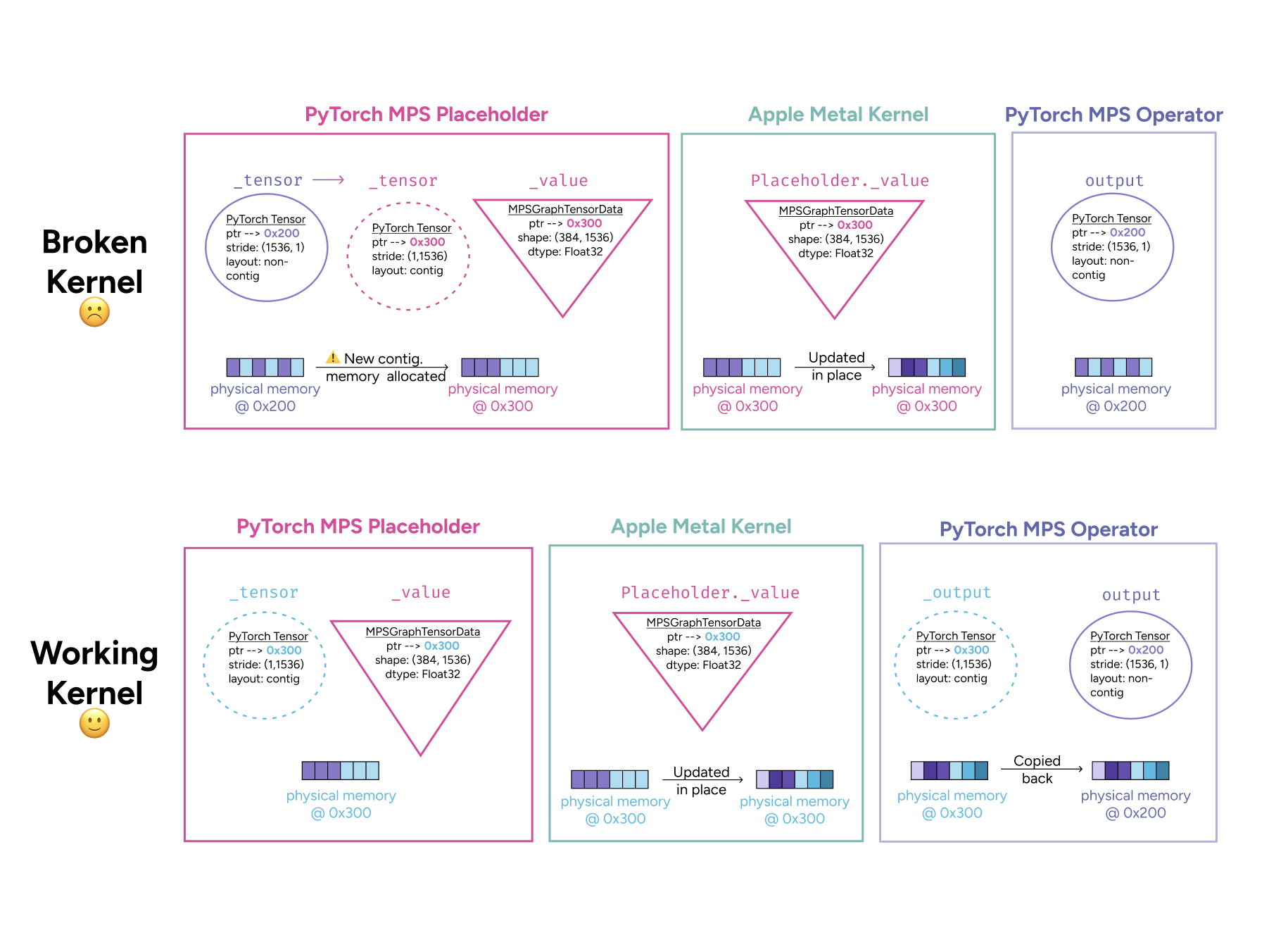
Debugging a PyTorch Bug: How a Training Loss Plateau Revealed Deep Framework Insights
A developer shares their experience debugging a training loss plateau in PyTorch that they initially assumed was their own mistake with hype
 elanapearl.github.io·7mo ago
elanapearl.github.io·7mo ago
PyTorch Monarch: A New Framework for Complex, Dynamic Machine Learning Workflows
PyTorch Monarch is a new framework designed to address the challenges of modern ML workflows that are heterogeneous, asynchronous, and dynam
 pytorch.org·7mo ago
pytorch.org·7mo ago
Luminal: High-Performance Deep Learning Library Using Search-Based Compilation
Luminal is a deep learning library that uses search-based compilation to achieve high performance. It's a Rust-based framework that allows u
 github.com·9mo ago
github.com·9mo ago