ONNX Runtime May Silently Convert Models to FP16 on Apple MPS Backend: Causes and Solutions
By
Two_hands
Sesame, salt, and substance. A flagship bake.
Summary
The article details a technical issue discovered in ONNX Runtime where models may be silently converted to FP16 (half-precision) when running on Apple's MPS (Metal Performance Shaders) backend, leading to different outputs compared to CPU execution. The author shares their experience benchmarking the EyesOff model and finding discrepancies between MPS and CPU outputs. The article provides technical analysis of the problem, explains why this silent conversion occurs, and offers solutions to prevent it, including specific code configurations and settings to enforce FP32 precision.
Key quotes
· 5 pulledI noticed that the metrics from the model ran on ONNX on MPS had a different output to those on ONNX CPU and PyTorch CPU and MPS.
When I say ORT and MPS, I mean the ONNX Runtime with the MPS execution provider.
The issue is that ONNX Runtime with MPS may silently convert your model to FP16, which can lead to different outputs and potentially affect model accuracy.
This silent conversion happens because MPS backend may automatically optimize for performance by using half-precision floating point (FP16) instead of single-precision (FP32).
To prevent this silent conversion, you need to explicitly configure ONNX Runtime to use FP32 precision when running on MPS.
You might also wanna read


tinygrad: A Simple Neural Network Framework Based on Three Core Operation Types
The article introduces tinygrad, a neural network framework that simplifies complex networks into three fundamental operation types: Element
Timber: AOT Compiler Converts Classical ML Models to Native C99 Code for High-Performance Inference
Timber is an open-source tool that compiles classical machine learning models (XGBoost, LightGBM, scikit-learn, CatBoost, ONNX) into native
 github.com·3mo ago
github.com·3mo ago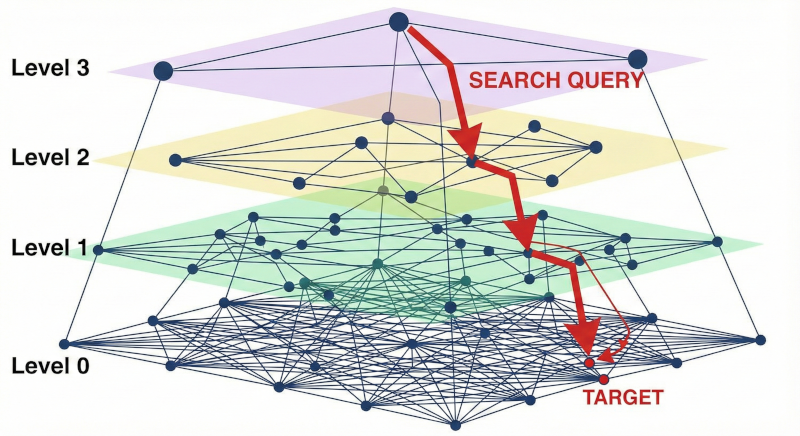
Implementing HNSW Algorithm for Vector Search in PHP: A Practical Guide
This article explains the Hierarchical Navigable Small World (HNSW) algorithm for efficient vector similarity search, contrasting it with br
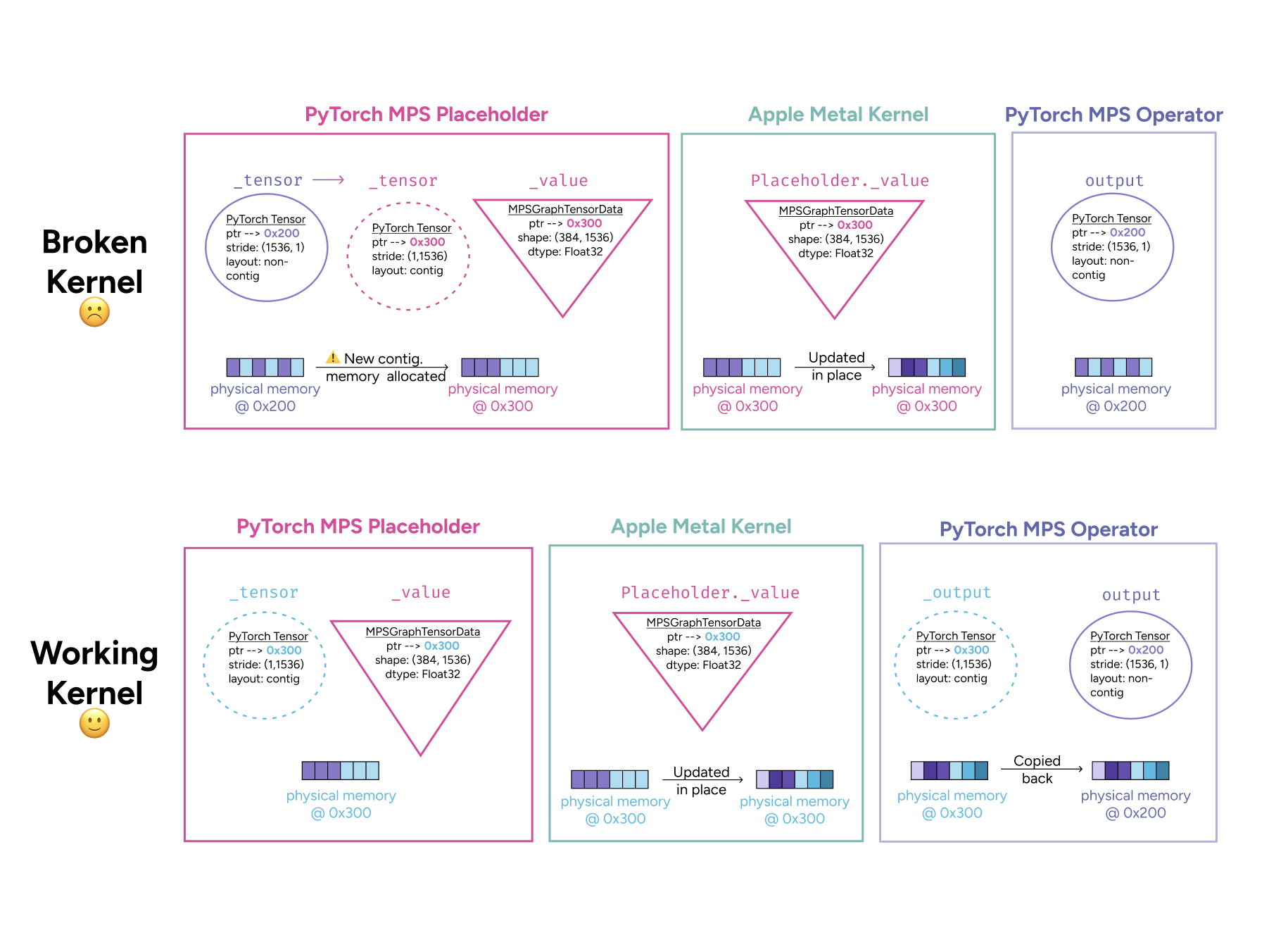
Debugging a PyTorch Bug: How a Training Loss Plateau Revealed Deep Framework Insights
A developer shares their experience debugging a training loss plateau in PyTorch that they initially assumed was their own mistake with hype
 elanapearl.github.io·7mo ago
elanapearl.github.io·7mo ago
PyTorch Monarch: A New Framework for Complex, Dynamic Machine Learning Workflows
PyTorch Monarch is a new framework designed to address the challenges of modern ML workflows that are heterogeneous, asynchronous, and dynam
 pytorch.org·7mo ago
pytorch.org·7mo ago
Luminal: High-Performance Deep Learning Library Using Search-Based Compilation
Luminal is a deep learning library that uses search-based compilation to achieve high performance. It's a Rust-based framework that allows u
github.com·9mo ago