Analysis predicts open source LLMs may catch frontier closed models by December 2026
By
Jamie DborinFounder & Member of Technical Staff, Doubleword
Summary
This article analyzes the performance gap between open weights LLMs and closed source LLMs using the Artificial Analysis Intelligence Index. It examines a plot showing how long it takes for open source models to catch up to frontier closed source models, and attempts to predict when an open source LLM will match frontier performance — forecasting a release around December 3, 2026.
Source

 Hacker NewsAnalysis predicts open source LLMs may catch frontier closed models by December 2026blog.doubleword.ai
Hacker NewsAnalysis predicts open source LLMs may catch frontier closed models by December 2026blog.doubleword.aiKey quotes
· 3 pulledI have seen a version of the above plot going around Twitter and wanted to dig a bit deeper into it.
What the plot above is showing is the gap between open weights LLMs and closed source LLMs.
It is a measure of how long it took for open source models to catch up to the new capabilities reached by the
You might also wanna read

OpenLIT Launches Open-Source Observability Platform with Custom Dashboards for LLM Applications
OpenLIT is an open-source observability and analytics platform for LLM applications that has launched a new version featuring fully customiz
 Product Hunt·10mo ago
Product Hunt·10mo ago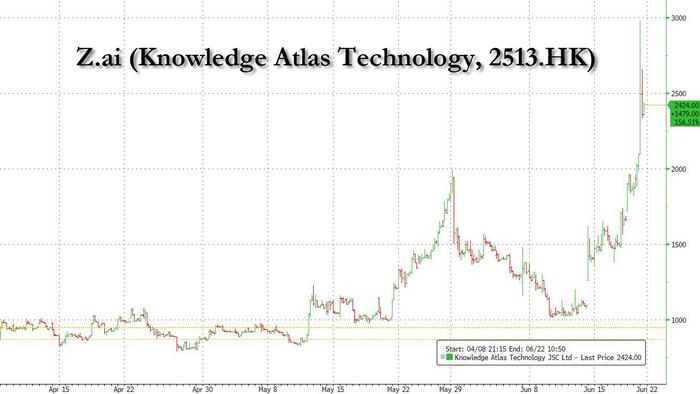
China's GLM 5.2 Open-Weight Model Challenges US AI Frontier, Analysts Say
China's Z.ai (formerly Zhipu) released the open-weight GLM 5.2 model on June 13, 2026, sparking comparisons to the "Deep Seek" moment for US
 zerohedge.com·13d ago
zerohedge.com·13d ago
MakeHub.ai: OpenAI-Compatible API for LLM Provider Arbitrage and Optimization
MakeHub.ai offers an OpenAI-compatible API endpoint that automatically routes requests to the cheapest and fastest LLM provider for each mod
 Product Hunt·1y ago
Product Hunt·1y ago
Chinese LLMs capture 61% of OpenRouter token traffic as US startups shift providers
Chinese-developed language models now account for roughly 61% of token consumption among the top 10 models on OpenRouter, a key AI API routi
 cryptobriefing.com·25d ago
cryptobriefing.com·25d ago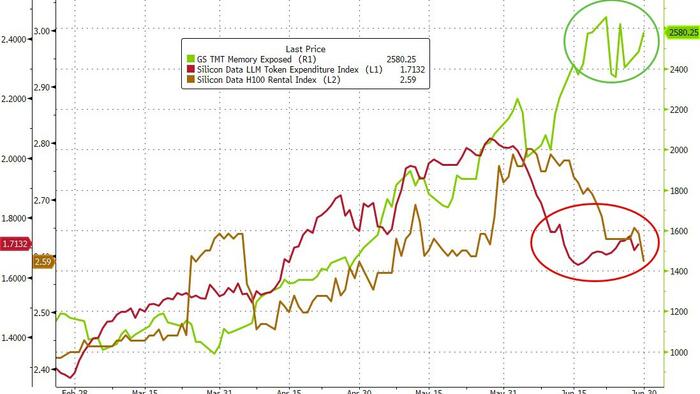
Meta pivots from frontier LLM race to cloud business, sending Nasdaq lower on AI compute oversupply fears
Meta has announced it is stepping back from the race to build a leading frontier large language model (LLM) and will instead pivot to buildi
zerohedge.com·4d ago
A11y LLM Eval update: Frontier models still fail at accessibility, but new "skills" approach shows promise
This article reports on the latest findings from the A11y LLM Eval project, a benchmark measuring how accessibly LLMs generate UI code. Key
 dev.to·7d ago
dev.to·7d ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.