A11y LLM Eval update: Frontier models still fail at accessibility, but new "skills" approach shows promise
By
Michael Fairchild
Summary
This article reports on the latest findings from the A11y LLM Eval project, a benchmark measuring how accessibly LLMs generate UI code. Key findings include: frontier models (GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro Preview) still default to inaccessible code, explicit accessibility instructions significantly improve output, and a new "skills" mechanic shows promise in bridging the gap. Manual testing remains essential despite improvements.
Source

 bskyA11y LLM Eval update: Frontier models still fail at accessibility, but new "skills" approach shows promisedev.to
bskyA11y LLM Eval update: Frontier models still fail at accessibility, but new "skills" approach shows promisedev.toKey quotes
· 3 pulledThe newest frontier models (GPT‑5.5, Claude Opus 4.7, Gemini 3.1 Pro Preview) still default to inaccessible code.
Explicit accessibility instructions can dramatically change that, and manual testing is still essential.
Skills change the game.
You might also wanna read

Enhancing Programmer Capabilities with Frontier LLMs
Frontier LLMs like Gemini 2.5 PRO can enhance programmer capabilities by quickly understanding code and solving bugs before deployment. The
antirez.com·11mo ago
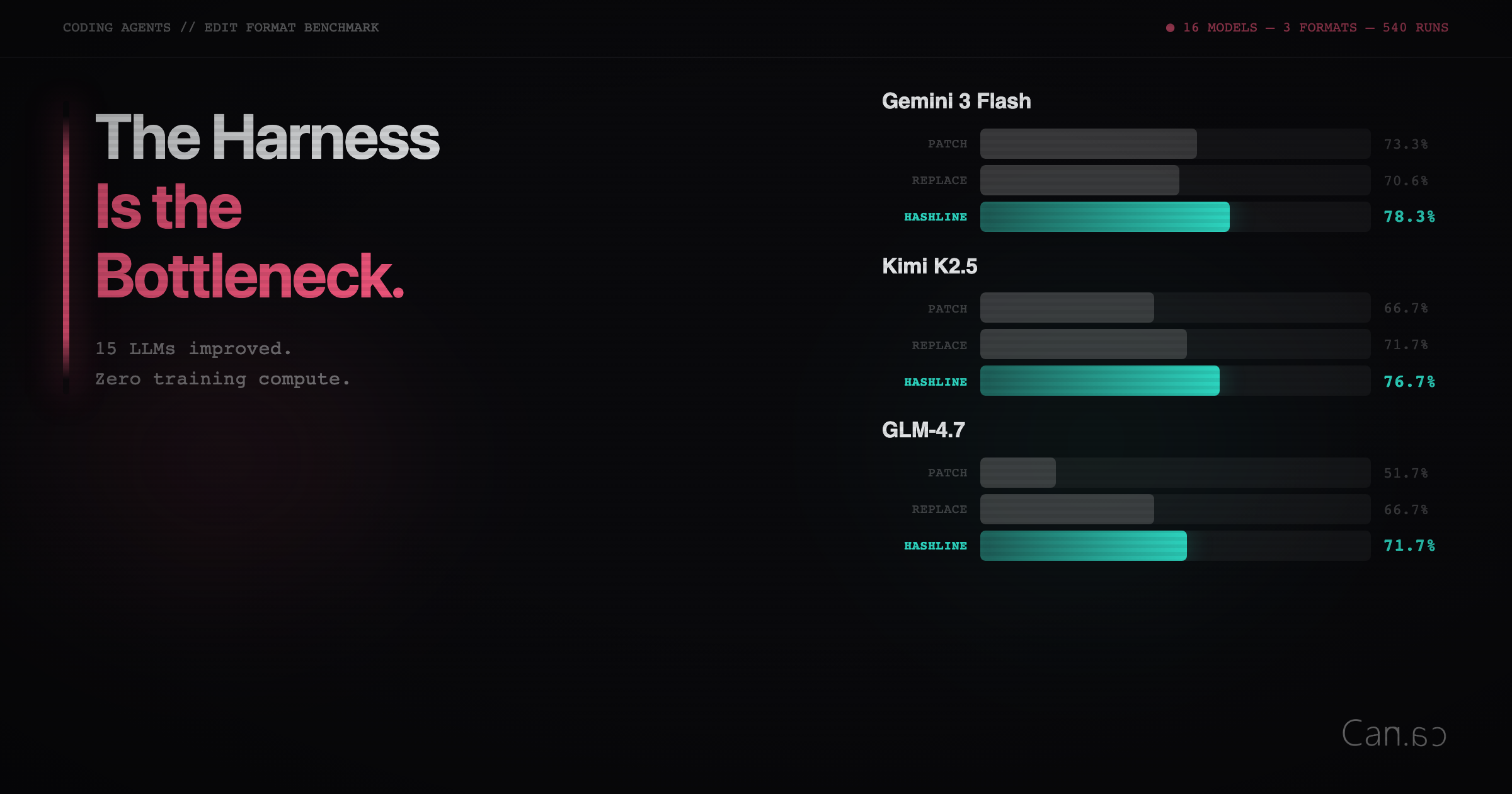
How Interface Design Impacts LLM Coding Performance More Than Model Selection
The article argues that the current focus on comparing which large language model (LLM) is best at coding is misguided because the real bott
 blog.can.ac·4mo ago
blog.can.ac·4mo ago
Benchmarking Frontier LLMs on Real-World CVE Patching: Mixed Results and Methodological Challenges
A comprehensive benchmark evaluation of five frontier large language models (LLMs) testing their ability to fix real-world security vulnerab

Study finds LLMs corrupt documents during delegated editing workflows, with frontier models averaging 25% content degradation
This paper introduces DELEGATE-52, a benchmark to evaluate how well Large Language Models (LLMs) handle delegated document editing tasks acr

Critical Analysis of LLM Limitations in Software Development
The article critiques the limitations and problems with Large Language Models (LLMs) and generative AI, using a personal experience with a n
 deobald.ca·4mo ago
deobald.ca·4mo ago
A Skeptical Look at GPT5's Coding Capabilities
The article is a critique of the capabilities of large language models (LLMs), specifically GPT5, in generating functional code. The author
 overengineer.dev·11mo ago
overengineer.dev·11mo ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.